Private AI: Running LLMs on Your Own Infrastructure — 60% Cheaper Than OpenAI
Why European enterprises are bringing AI in-house, and the concrete economics behind the shift.
The $8.4 Billion Wake-Up Call
Enterprise spending on large language model APIs doubled to $8.4 billion in 2025, and 72% of companies plan to increase their AI budgets further this year. But behind the adoption surge, a quieter counter-movement has been building. According to Kong's 2025 Enterprise AI report, 44% of organizations cite data privacy and security as the top barrier to LLM adoption. Every prompt sent to OpenAI, Anthropic, or Google travels through external servers, governed by third-party retention policies and subject to jurisdictions that may not align with your own.
For European enterprises — operating under the world's most stringent regulatory framework — this creates a fundamental tension. You need AI to stay competitive, but you need data sovereignty to stay compliant. The solution isn't to avoid AI. It's to own it.
Private AI — the practice of deploying large language models on infrastructure you control — has matured from an experimental curiosity into a viable, often superior alternative to commercial API services. Open-source models now match or exceed GPT-4-level performance on most enterprise tasks. Deployment tooling has simplified dramatically. And the economics, once prohibitive, now favor self-hosting at scale: organizations processing high volumes of tokens daily can achieve 40–60% cost reductions compared to commercial APIs, with some reporting savings as high as 83%.
This article provides a concrete, numbers-driven analysis of when and why Private AI makes sense — covering the regulatory landscape that makes it urgent for EU companies, the true total cost of ownership, the technical stack required for production deployment, and the fine-tuning capabilities that turn a generic model into a competitive advantage.
The Regulatory Pressure Cooker: GDPR Meets the EU AI Act
European enterprises don't just prefer data sovereignty — they are increasingly required to demonstrate it. The regulatory environment in 2026 creates compounding compliance obligations that make third-party AI APIs a growing liability.
GDPR: The Baseline That Still Bites
The General Data Protection Regulation remains the foundation. Every AI system processing personal data of EU residents must establish a lawful basis, implement data protection by design and by default, and be able to demonstrate compliance on demand. When you send customer data through an external LLM API, you introduce a data processor (the API provider) into your processing chain. This requires a Data Processing Agreement, documentation of the legal basis for the transfer, and ongoing assurance that the provider's retention and training practices don't violate your obligations.
Self-hosting eliminates this entire category of risk: your prompts never leave your network, and there is no third-party processor to audit.
The EU AI Act: Fines That Exceed GDPR
The EU AI Act — the world's first comprehensive AI regulation — has been phasing in obligations since August 2024, with the most critical deadline arriving on August 2, 2026. On that date, requirements for high-risk AI systems under Annex III become fully enforceable. The penalty structure exceeds even the GDPR: up to €35 million or 7% of global annual turnover for prohibited AI violations, and up to €15 million or 3% for non-compliance with high-risk system obligations.
| Date | Milestone | Impact |
|---|---|---|
| Aug 2024 | AI Act enters into force | Legal framework established |
| Feb 2025 | Prohibited AI practices enforced | Social scoring, manipulative AI banned |
| Aug 2025 | GPAI transparency obligations | LLM providers must disclose training data |
| Aug 2, 2026 | High-risk AI full compliance | Conformity assessments, EU database registration |
| Aug 2027 | AI in regulated products | Medical devices, vehicles with embedded AI |
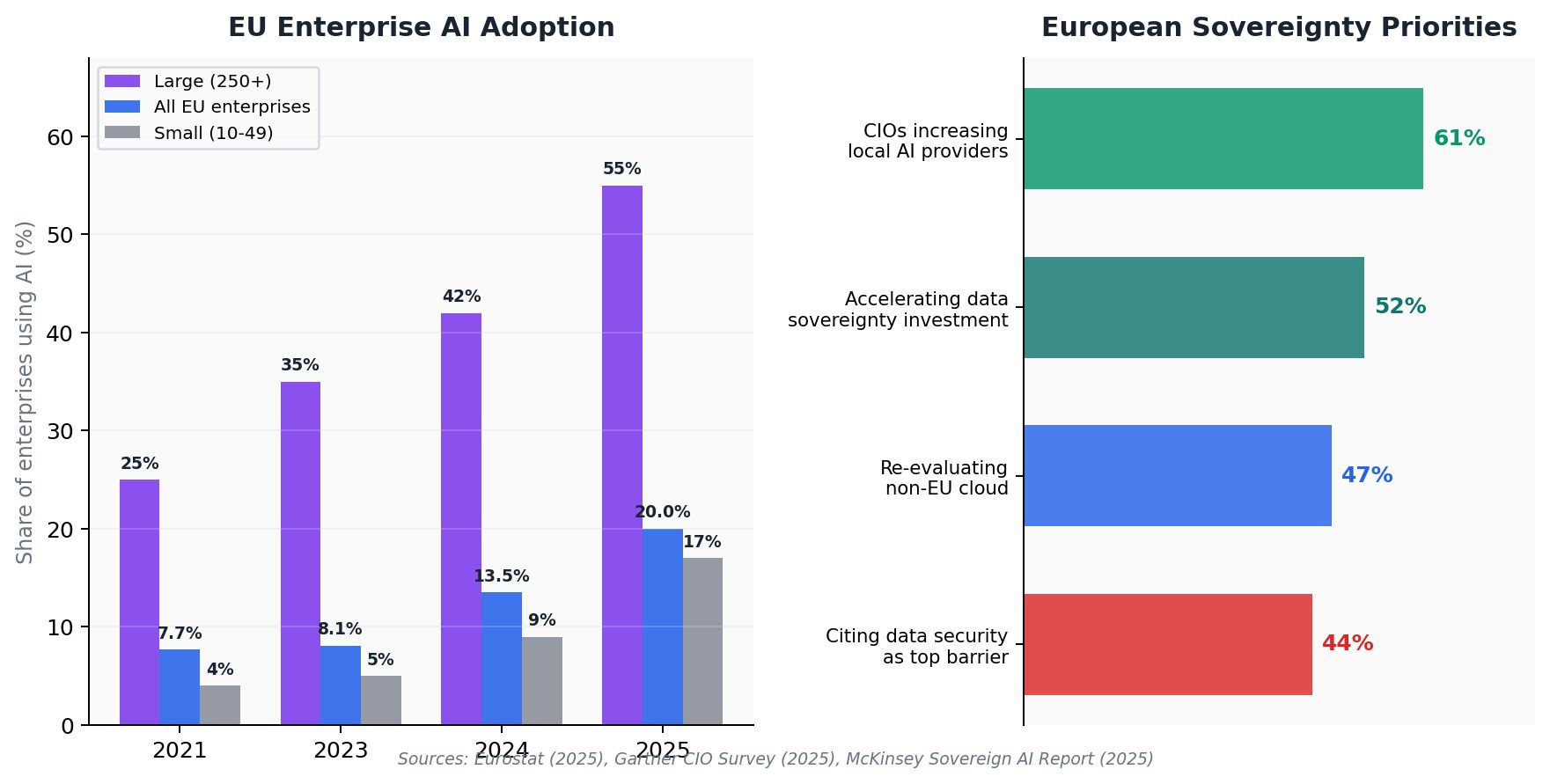
Data Sovereignty Has Become a Board-Level Priority
According to Gartner's 2025 CIO & IT Leader Survey, 61% of CIOs and IT decision-makers in Western Europe plan to increase their reliance on local cloud and AI providers. Furthermore, 52% expect to accelerate investment in data sovereignty initiatives, and 47% are actively reevaluating non-European cloud dependencies. McKinsey estimates sovereign AI capabilities in Europe could unlock up to €480 billion in value annually by 2030.
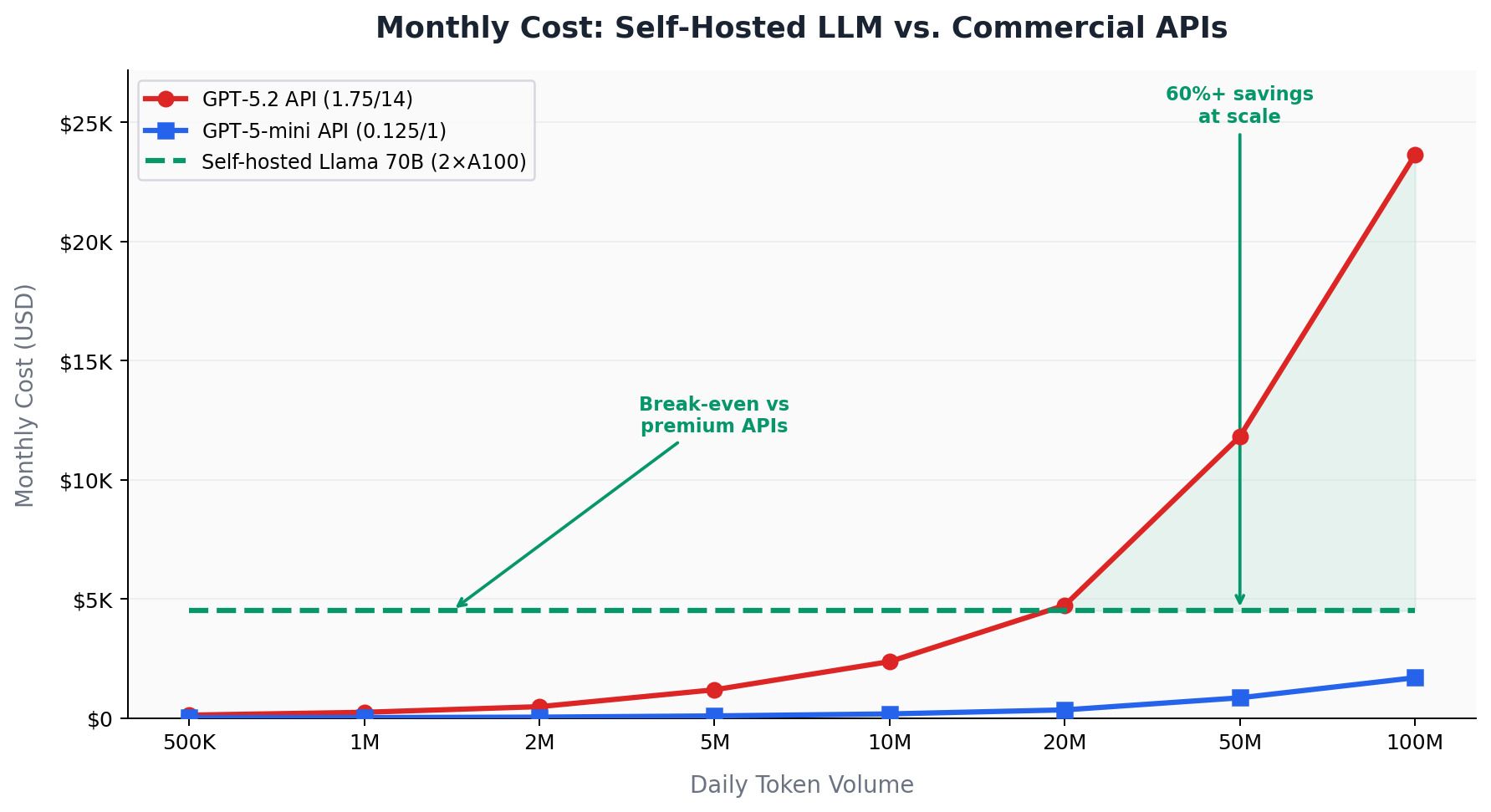
The Cost Equation: When Self-Hosting Beats the API
The economics of Private AI depend on three variables: your token volume, the model tier you're comparing against, and your ability to maintain high GPU utilization. Understanding the crossover points is essential.
API Pricing in 2026: A Highly Stratified Market
Commercial LLM API pricing has stratified dramatically. OpenAI's GPT-5.2 costs $1.75 per million input tokens and $14.00 per million output tokens. GPT-5-mini runs $0.125/$1.00 — a 14x difference. DeepSeek V3.2 offers competitive quality at just $0.14/$0.28 per million tokens.
| Model / Option | Input / 1M tok | Output / 1M tok | Monthly @ 1M/day |
|---|---|---|---|
| GPT-5.2 (premium) | $1.75 | $14.00 | ~$7,875 |
| GPT-5-mini (budget) | $0.125 | $1.00 | ~$563 |
| DeepSeek V3.2 | $0.14 | $0.28 | ~$210 |
| Self-hosted Llama 70B | Fixed | Fixed | ~$4,500 |
The Break-Even Analysis
Against premium models like GPT-4o or Claude Sonnet ($7.50–$9.00 per million tokens blended), self-hosting breaks even at approximately 5–10 million tokens per month. Against budget APIs like GPT-4o mini or DeepSeek ($0.15–$0.40 per million tokens), the break-even jumps to 50–100 million tokens monthly. For European operators at $0.25–$0.30/kWh, power costs push the break-even 40–60% higher.
Rule of thumb: Organizations processing over 2 million tokens daily should seriously evaluate self-hosting. Below that threshold, API costs are typically lower. Above 100 million tokens daily, self-hosting can save 40–60% — particularly against premium-tier models.
Hidden Costs You Cannot Ignore
Raw GPU costs represent only 30–40% of true self-hosting infrastructure investment. A realistic TCO multiplier is 1.3x to 2.0x the base GPU cost. Engineering labor is often the largest hidden cost — a mid-level MLOps engineer in Europe runs €80,000–120,000 annually. Power and cooling run 1.5–2x the rated GPU power draw. Hardware depreciation: a $30,000 H200 GPU loses approximately $833 per month over 36 months.
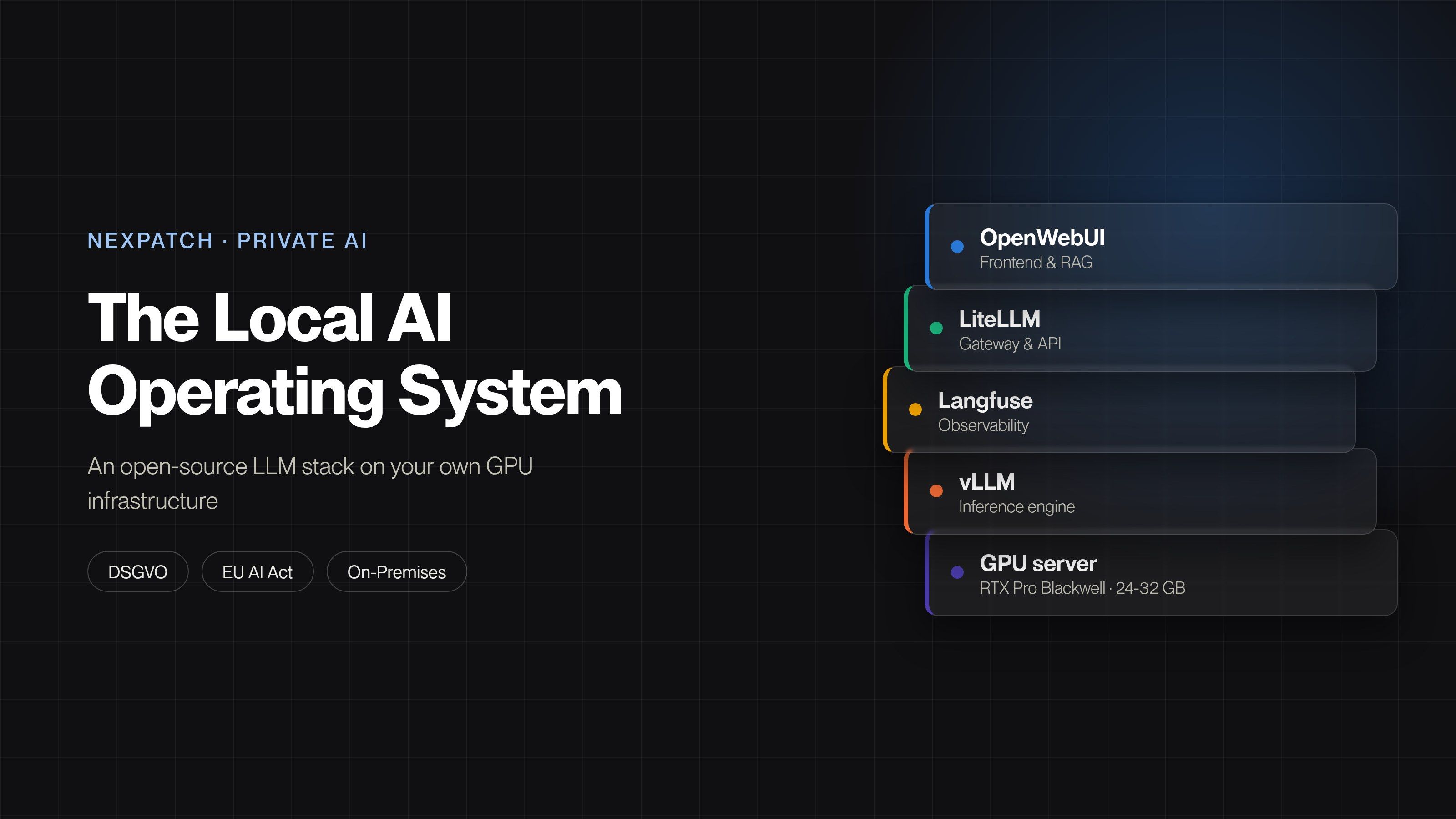
The Technical Stack: From Model Selection to Production Serving
Deploying a private LLM in production is no longer the heroic engineering effort it was in 2023. The tooling ecosystem has matured dramatically, and a well-chosen stack can go from zero to production in days.
Choosing the Right Open-Source Model
The quality gap between open-source and proprietary models has narrowed significantly. Leading options in early 2026 include Meta's Llama 3.3 (8B and 70B), Alibaba's Qwen 2.5 (up to 72B), DeepSeek V3.2 (sparse MoE), and OpenAI's gpt-oss-120B — the company's first fully open-weight model since GPT-2, released under Apache 2.0. Qwen 2.5-72B achieves 95%+ parity with GPT-4 on MMLU and HumanEval. For structured tasks, open-source models handle 80%+ of enterprise use cases without meaningful quality loss.
Inference Engines: Ollama for Development, vLLM for Production
| Criterion | Ollama | vLLM |
|---|---|---|
| Primary use | Dev, prototyping, single-user | Production, high concurrency |
| Setup | Single command | CUDA, drivers, Python config |
| Throughput (70B) | ~484 tok/s | ~8,033 tok/s (16.6x) |
| Concurrency | Collapses at 128 users | 100% success at 128 users |
| OpenAI-compatible | Yes | Yes |
| Key technology | llama.cpp wrapper | PagedAttention, continuous batching |
The OpenAI-Compatible API: Your Migration Insurance
Whether you deploy with Ollama, vLLM, or LM Studio, your application code remains essentially the same. The standard /v1/chat/completions endpoint works identically across all providers — meaning you can start with commercial APIs, migrate incrementally to self-hosted models, and switch between providers without application rewrites.
from openai import OpenAI # Same client library, different base URL client = OpenAI( base_url="https://your-internal-llm.company.eu:8000/v1", api_key="your-internal-token" ) response = client.chat.completions.create( model="meta-llama/Llama-3.3-70B-Instruct", messages=[ {"role": "system", "content": "You are a helpful assistant."}, {"role": "user", "content": "Summarize the Q4 compliance report."} ], temperature=0.1 ) # Data never leaves your network.
Fine-Tuning: Where Private AI Becomes a Competitive Moat
Perhaps the most compelling strategic argument for Private AI isn't cost or compliance — it's customization. Fine-tuning transforms a general-purpose model into a domain specialist that understands your terminology, follows your processes, and produces outputs calibrated to your standards.
LoRA: Fine-Tuning Without the Expense
Low-Rank Adaptation (LoRA) has revolutionized fine-tuning economics. Instead of retraining all parameters, LoRA trains small adapter modules representing just 0.1% of total parameters. For a 70B model, that's ~70 million parameters consuming 0.14 GB. Fine-tuning can be completed on a single GPU in hours at $15–40 per run. Together AI's research shows fine-tuned 27B models can outperform Claude Sonnet 4 by 60% on specialized tasks while running 10–100x cheaper.
The key difference: when you fine-tune through OpenAI, the resulting model is proprietary — accessible only through their API. When you fine-tune open-source models with LoRA, the adapter is yours: deploy it anywhere, version-control it, run it with zero per-token charges.
Where Fine-Tuning Creates Defensible Value
The highest-ROI use cases share common characteristics: domain-specific terminology, consistent output formatting, and high-volume repetitive tasks. In legal departments, fine-tuned models extract contract clauses with 30–40% higher accuracy. In healthcare, models trained on clinical notes follow documentation standards that general models violate. In customer service, fine-tuned models maintain brand voice and escalation protocols that prompt engineering achieves only inconsistently.
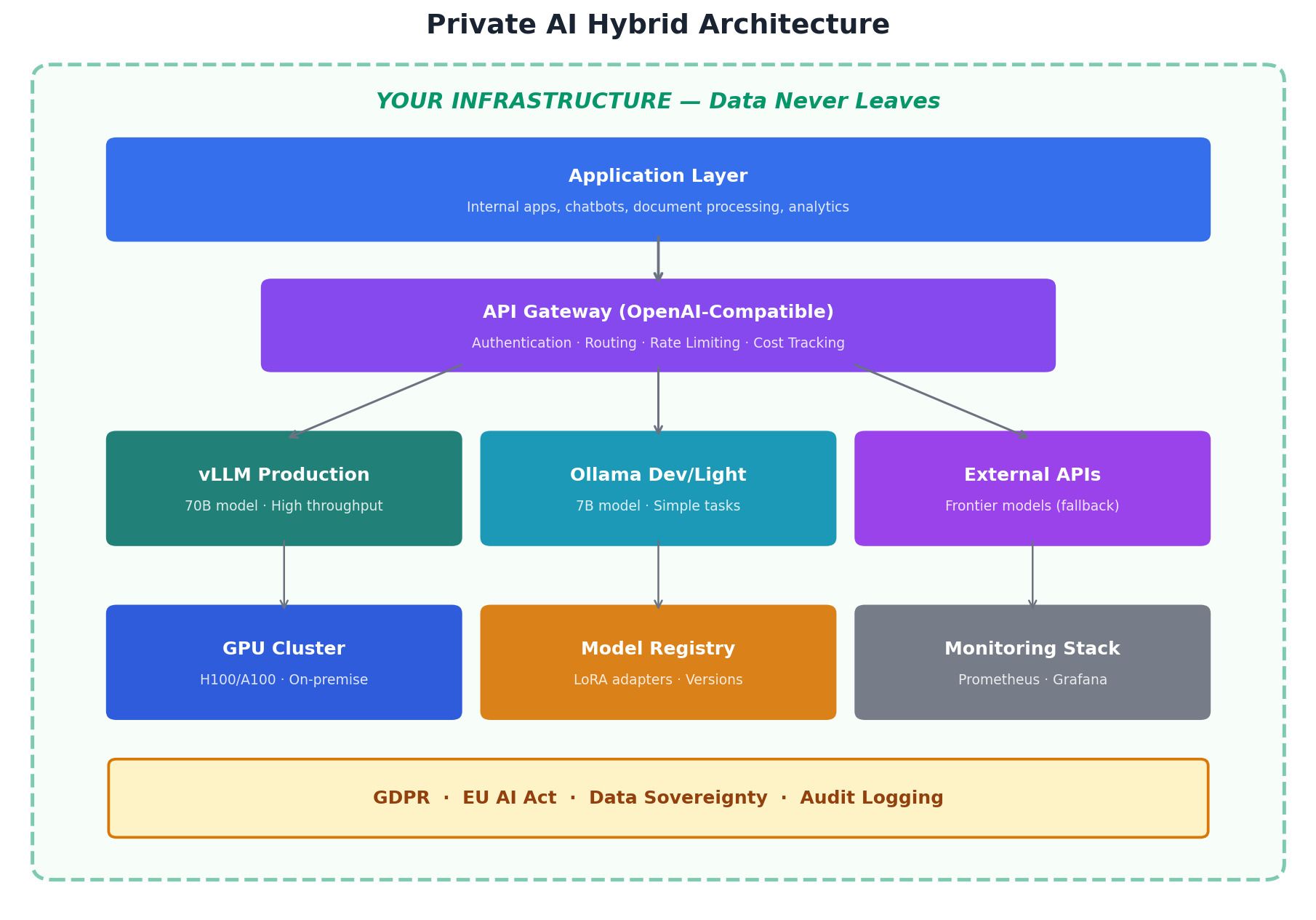
The Hybrid Architecture: The Pragmatic Path Forward
The most effective architecture combines private models for high-volume, sensitive, or domain-specific workloads with commercial APIs for frontier capabilities and rapid experimentation. An API gateway routes each request based on data sensitivity, task complexity, and cost efficiency.
A Practical Migration Roadmap
| Phase | Timeline | Activities |
|---|---|---|
| 1. Audit | Wk 1–4 | Inventory LLM usage. Classify by sensitivity, volume, quality needs. Map to AI Act compliance. |
| 2. Pilot | Wk 5–12 | Deploy Ollama + vLLM on GPU infra. Start with one low-risk, high-volume use case. Shadow mode for 2 weeks. |
| 3. Migrate | Wk 13–24 | Move validated use cases. Implement API gateway. Begin fine-tuning on highest-value domain. |
| 4. Optimize | Ongoing | Expand use cases. Add batch processing, caching, model cascading. Evaluate smaller models. |
Conclusion: Sovereignty Is the New Scalability
The shift to Private AI is not primarily a cost optimization — though the savings are real. It is a strategic repositioning that addresses regulatory compliance, data sovereignty, competitive differentiation through fine-tuning, and operational control.
European enterprises face a unique window of opportunity. The EU AI Act's August 2026 deadline creates urgency. Open-source models have reached quality parity. Deployment tooling has simplified to where a competent DevOps team can have production inference running in days. And cost economics now favor self-hosting for any organization processing meaningful AI workloads.
Private AI is not about rejecting the cloud. It's about having the infrastructure, skills, and strategic clarity to deploy AI on your terms — choosing external services because they're genuinely better, not because they're the only option. In a world where AI capabilities increasingly define competitive advantage, owning your AI stack is as fundamental as owning your data.