
Private AI Agent Systems with Orchestrated Specialist Models
A deep research analysis of architecture, research and practice. Status: May 2026.
The architecture of generative AI has changed substantially over the last 24 months. In 2023, the dominant assumption was that the best system was the largest possible monolithic model. From 2024 to 2026, a different pattern became practical: heterogeneous agent collectives, meta-agents that orchestrate specialists and locally hostable Small Language Models (SLMs) that handle routine work with better privacy and cost control.
The reason is straightforward: not every task needs a 70B or frontier model. Agentic systems create many repetitive, narrow and schema-bound calls: tool use, extraction, classification, validation, small code fragments, OCR cleanup, retrieval and lightweight planning decisions. In exactly those calls, specialized SLMs are often strong enough, faster, cheaper and easier to govern. NVIDIA Research's position paper "Small Language Models are the Future of Agentic AI" captures the point well: SLMs are sufficiently powerful, inherently more suitable and necessarily more economical for many invocations in agentic systems.

For private, on-premise AI systems, this creates a new reference pattern: a central conductor decomposes tasks, routes them to specialist models, connects local data through MCP, controls latency and cost, and merges results under explicit guardrails.
From Monolithic Models to Agent Collectives
The difference between a single universal model and an orchestrated agent system is more than a technical implementation detail. It changes operations, compliance and economics.
| Dimension | Monolithic LLM | Orchestrated multi-agent system |
|---|---|---|
| Inference cost | Every token activates a very large parameter set | SLMs handle routine work, larger models handle edge cases |
| Hardware | Usually cloud API or A100/H100 class | RTX 4090, Apple Silicon or local GPU workstations for many tasks |
| Specialization | Generalist with prompting | Domain-specific LoRA/QLoRA adapters per role |
| Privacy | Data often leaves the organization | Fully on-premise or controlled hybrid deployment |
| Scaling | Expensive vertical scaling | Agents and models scale horizontally |
| Maintainability | Behavior is embedded in one large model | Submodels, tools and policies can be updated separately |
The pattern is related to Mixture-of-Experts (MoE). MoE activates only selected experts inside a model for each token. Multi-agent systems do the same at system level: they activate only the capabilities a task actually needs. Concepts such as top-k routing, capacity factor, load balancing and sparse activation move from model architecture into enterprise system architecture.
Scientific Foundations
Mixture-of-Experts as the Predecessor
The MoE idea goes back to Jacobs et al. and became mainstream through Switch Transformer, Mixtral and DeepSeek-V3. A gating network decides which experts are activated for a token. Recent surveys on MoE inference optimization show that efficient routing can reduce compute by 30 to 50 percent, while hardware optimizations can add another 2x to 4x acceleration.
For agents, the lesson is clear: routing is not a side feature. It is the core efficiency layer. A private agent system must decide when a 7B tool caller is enough, when a 14B planner is useful and when a 70B model justifies the additional cost.
Multi-Agent Reinforcement Learning Meets LLMs
LLM-based multi-agent reinforcement learning explores how language models can act as coordinators, critics or speakers in cooperative environments. Methods such as Criticize-Reflect and MAGRPO show that collaborative coding and writing tasks can be improved by trained multi-agent cooperation compared with single-agent setups.
Router research is particularly relevant for enterprise systems. xRouter, HierRouter and RL-Conductor model delegation as a decision under cost, quality and latency constraints. The finding is consistent: end-to-end trained routers can make more context-sensitive choices than fixed heuristics. The risk is routing collapse, where the router overuses the strongest and most expensive model. Cost-aware reward shaping and skill-based orchestration are designed to avoid this failure mode.
Tool-Augmented Agents
Toolformer showed that LLMs can learn to call external APIs through self-supervised annotations. ReAct, ToolLLM, ToolAlpaca, ToolMaker and Tool-MVR extended the pattern. The direction is obvious: agents are less valuable when they only generate text and much more valuable when they can safely operate databases, code, files, search indexes and internal APIs.
For private systems, tool calling must be standardized, observable and permissioned. A local Postgres MCP server, a filesystem MCP server and a Git MCP server are not convenience features. They are the working limbs of the agent system.
NVIDIA Nemotron 3 Nano Omni as a New Building Block
NVIDIA Nemotron 3 Nano Omni is a useful example of how quickly specialist models are changing the shape of private agent systems. It is not just a vision-language model. It is an omni-modal building block for documents, images, audio, video and GUI agents. According to NVIDIA and Hugging Face, it is designed for five workload classes: real-world document analysis, automatic speech recognition, long audio-video understanding, agentic computer use and general multimodal reasoning.
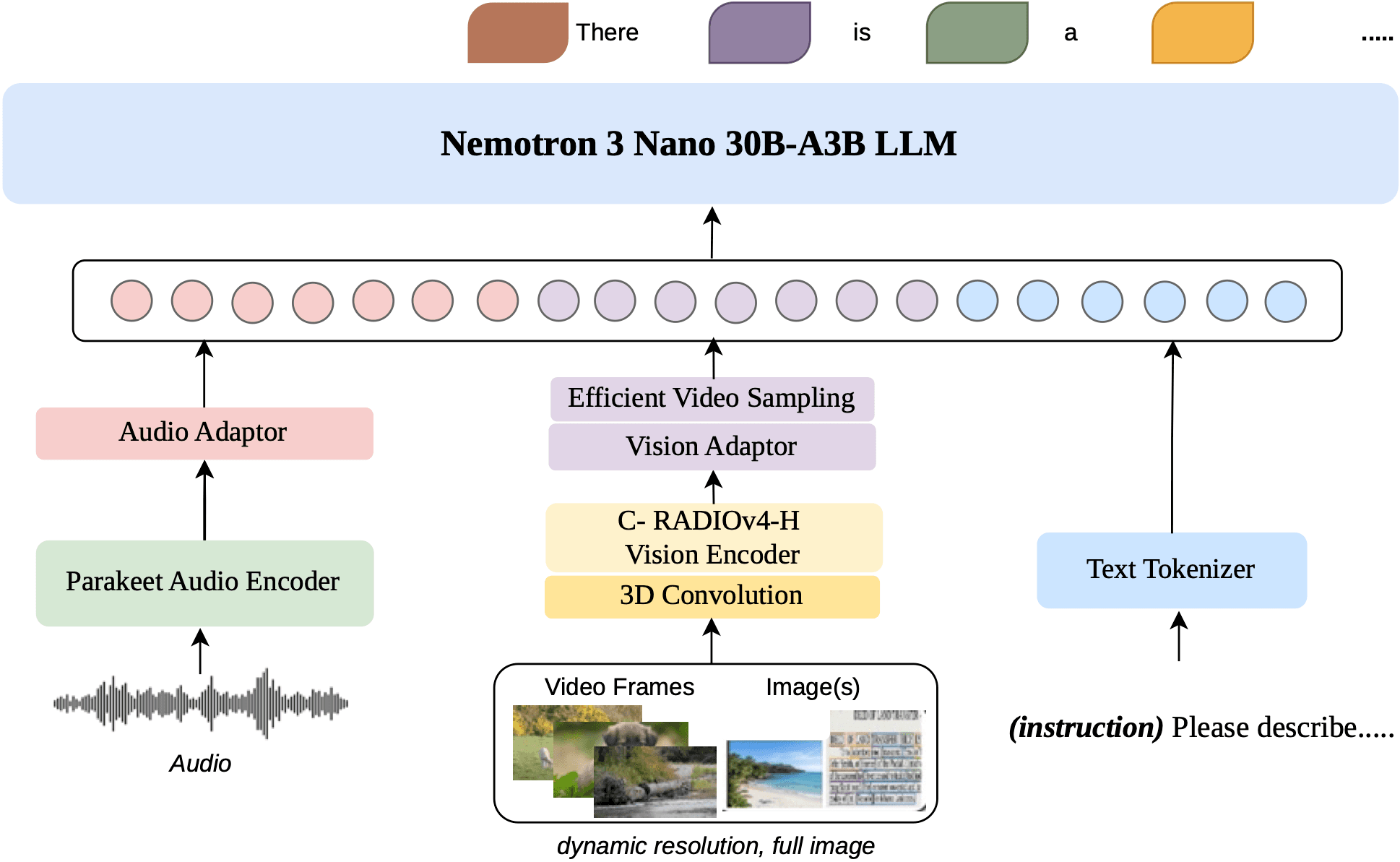
Image source: NVIDIA / Hugging Face, "Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents", Figure 2.
Architecturally, Nemotron 3 Nano Omni is especially relevant because it combines several trends that also matter for private multi-agent systems. Its Nemotron 3 Nano 30B-A3B language backbone combines Mamba state-space layers, Mixture-of-Experts and grouped-query attention. NVIDIA describes 23 Mamba layers, 23 MoE layers with 128 experts and top-6 routing, plus 6 GQA layers. For modalities, the system uses C-RADIOv4-H as the vision encoder and Parakeet-TDT-0.6B-v2 as the audio encoder, connected through lightweight MLP projectors into a shared token space.
For enterprise agents, three details matter more than raw model size:
| Nemotron component | Why it matters for private agent systems |
|---|---|
| Dynamic resolution | Documents, tables, charts and screenshots can be processed with fine detail and layout context. |
| Native audio and video processing | Meetings, screen recordings, support videos and spoken commentary can be interpreted jointly with visual signals, not only transcribed. |
| Multimodal RL and verifiers | Training across images, video, audio and text, including abstention when evidence is insufficient, fits regulated workflows. |
This changes the model portfolio for private agent systems. In addition to coding, tool-calling and guardrail models, modern deployments increasingly need a multimodal specialist that can treat long PDFs, screenshots, audio and video as a shared evidence layer. Nemotron 3 Nano Omni shows what such a component can look like: not a replacement for the conductor, but a capable agent inside the model pool.
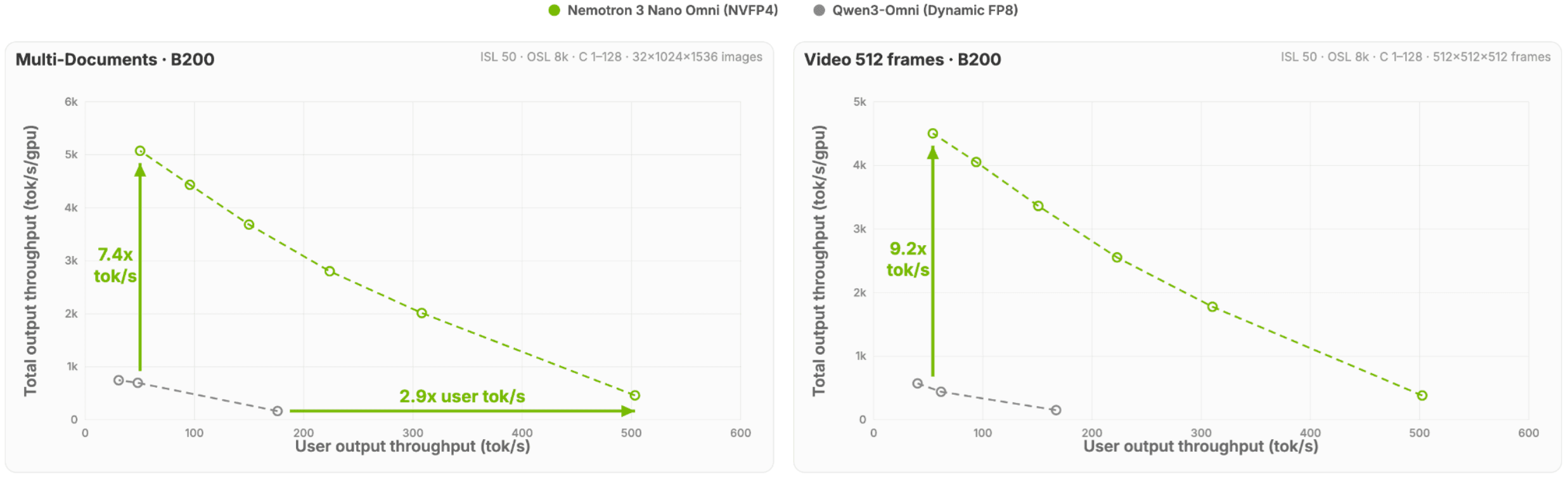
Image source: NVIDIA / Hugging Face, "Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents", Figure 1.
The training and data story is equally important. NVIDIA describes synthetic data pipelines with NeMo Data Designer, including about 11.4 million synthetic QA pairs from real-world PDFs for long-context document reasoning. According to the article, this produced a 2.19x improvement on MMLongBench-Doc. For enterprises, that direction matters: private agent systems will not be only about choosing models, but also about data pipelines, synthetic evaluation sets and continuous quality measurement.
Key Research and Practical Implications
| Research stream | Examples | Practical implication |
|---|---|---|
| SOP-based orchestration | MetaGPT, ORCH | Interpretable workflows for regulated processes |
| Optimizable agent graphs | GPTSwarm | Workflows can be improved and versioned as graphs |
| Multimodal agents | OmniNova, training-free multimodal orchestration | Vision, TTS, text and tools can be combined through one controller |
| Cost-aware routing | FrugalGPT, xRouter, HierRouter | Start with smaller models, escalate only on low confidence |
| Skill-based orchestration | SkillOrchestra | Routing by capability reduces training cost and routing collapse |
| Self-evolving agents | Fang et al., AgentNet | Long-term systems may evolve dynamic topologies instead of fixed teams |
| Evaluation | AgentBench, MASLab | Reproducibility and benchmarks become production requirements |
FrugalGPT remains the methodological base for many routers: requests are first sent to cheaper models and escalated only when confidence is insufficient. In enterprise architectures, this is the right default because it serves cost and privacy goals at the same time.

Open-Source Frameworks for Practice
| Framework | Paradigm | Strengths | Typical use case |
|---|---|---|---|
| LangGraph | Graph-based, stateful | Fine-grained control, parallelism, stable state models | Complex workflows with many steps |
| AutoGen | Conversational, role-playing | Fast prototyping, agent debates | Research and collaborative reasoning |
| CrewAI | Role-based, YAML-friendly | Low learning curve, readable configuration | Small to medium agent teams |
| LlamaIndex AgentWorkflows | RAG-centric | Deep knowledge-base integration | Question answering and document workflows |
| Semantic Kernel | Plugin architecture | Enterprise integration, .NET proximity | Microsoft-centric stacks |
| Strands Agents SDK | Loop-based, agents as tools | Multimodal and cloud/hybrid-friendly | AWS-adjacent agentic workloads |
| GPTSwarm | Optimizable graph | Self-improving workflows through graph optimization | Research and automatic workflow generation |
A pragmatic 2026 recommendation is to use LangGraph as the backbone, specialized AutoGen debates as subgraphs, CrewAI for simple internal tools and MCP as the bridge to data sources and systems. That keeps the architecture controllable without ignoring current research momentum.
MCP and A2A: Protocols for the Agent Era
MCP is the vertical connection: an agent accesses tools and data below its execution layer through a standard protocol. A2A is the horizontal connection: agents discover and assign work to other agents through defined capabilities, task lifecycles and message formats.
| Protocol | Direction | Core function | Relevance for Private AI |
|---|---|---|---|
| MCP | Vertical | Connect tools, data sources and local systems | Local data stays local, tool use becomes auditable |
| A2A | Horizontal | Agents communicate across organizational boundaries | Basis for federation with partners or subsidiaries |
The combination matters for private agent systems. MCP wraps Postgres, Git, filesystem access, vector stores and internal REST APIs. A2A creates a path toward future federation. Security risks still need serious treatment: prompt injection, tool spoofing, data exfiltration through tool combinations and cross-agent contamination belong in every threat model.
Reference Architecture for a Private Agent System
A realistic on-premise setup for a medium-sized organization can run on one or two GPU workstations with 48 GB VRAM each, or a small cluster of RTX 6000 Ada, L40S or comparable cards. The decisive factor is not maximum model size. It is disciplined routing.

Model Portfolio
| Role | Example model | Size | Quantization | Task |
|---|---|---|---|---|
| Orchestrator / router | Qwen2.5-7B-Instruct or Phi-4 | 7-14B | INT8 | Decompose tasks, plan delegation |
| Coding specialist | DeepSeek-Coder-V2-Lite or Qwen2.5-Coder-7B | 7B | INT4 | Scripts, SQL, tests, refactorings |
| Vision / multimodal | Qwen2.5-VL-7B-Instruct | 7B | INT4 | OCR, tables, screenshots, diagrams |
| Tool caller | Hammer-2.0-7B or Llama-3.1-8B function-call fine-tune | 7-8B | INT4 | Structured tool calls |
| Planning agent | GLM-4-9B or Llama-3.3-70B on demand | 9-70B | INT4/Q5 | Difficult reasoning and escalation |
| Embeddings | bge-m3 or Nomic Embed | about 0.5B | FP16 | Retrieval and memory |
| Guardrail | Llama-Guard-3-8B | 8B | INT8 | Policy, safety, pre- and post-checks |
A Practical Data Flow
A request such as "Analyze the contract changes in these three PDFs and create a Python script that writes the clauses into Postgres" should run roughly like this:
- The conductor identifies vision extraction, reasoning, coding and database inspection as required skills.
- A vision agent extracts tables and clauses through OCR and writes structured JSON into episodic memory.
- A reasoning agent compares versions and identifies relevant clause differences.
- A coding agent generates the SQL insert script.
- A tool caller checks the Postgres schema through MCP and proposes migrations if needed.
- A guardrail checks for SQL injection patterns, data leakage and policy violations.
- The conductor synthesizes the answer and offers Apply, Review or Reject.
The largest model is used only when confidence, novelty or risk justify it. In many workloads, this architecture saves 60 to 80 percent of inference cost compared with a pure 70B setup.
Risks and Countermeasures
| Risk | Symptom | Countermeasure |
|---|---|---|
| Latency overhead | Each agent hop adds 200-800 ms | Hop budget, parallelization, early stopping |
| Reasoning drift | More than 10 agent transitions degrade quality | Limit the DAG, validate intermediate results |
| Cascading hallucinations | One error is inherited by later agents | SOPs, critic agents, Tool-MVR, consensus layer |
| Routing collapse | Router overuses the most expensive model | Cost-aware rewards, SkillOrchestra pattern, budget limits |
| State management | Memory and permissions become inconsistent | Event log, explicit context contracts, least privilege |
| MCP tool injection | Malicious tools or prompts abuse permissions | Signed tools, allowlisting, sandboxing, audit log |
The most important operational layer is observability. Without tracing, a multi-agent system becomes a black box quickly. Every delegation should record request ID, model, prompt hash, tool call, cost, latency, policy decision and result status.
Trends for 2026 and 2027
The first agent wave was prompt engineering. The second wave trains orchestrators with reinforcement learning over frozen experts. This is attractive because teams do not need to retrain foundation models. They optimize delegation between existing models.
In parallel, the discussion is moving from tool to society. Work such as Generative Agents, Generative Agent Simulations of 1,000 People and AgentNet shows that agents are not only productivity tools. They are also simulation and organizational objects. Enterprises will need to design, monitor and govern agent teams similarly to how they govern microservice landscapes today.
For Europe, privacy remains a major driver. Fully on-premise deployment will remain relevant for government, banking, pharma and defense. Hybrid architectures will be the pragmatic default for most organizations: sensitive data local, heavy reasoning through sovereign cloud endpoints or confidential computing.
Conclusion
Orchestrated specialist models are no longer speculative in 2026. They are a production-ready architecture class. The lesson from MoE, FrugalGPT, xRouter, SkillOrchestra, LangGraph, MCP and A2A is consistent: one large model is rarely the best economic or regulatory answer.
Private agent systems should start SLM-first, escalate to large models selectively, use MCP as the tool and data standard, watch A2A as the federation path, limit agent hops and build observability from the beginning.
The future does not belong only to the largest model. It belongs to architectures that know which model is enough for the task at hand.
Sources and Further Reading
- Belcak et al.: "Small Language Models are the Future of Agentic AI" - https://arxiv.org/abs/2506.02153
- Liu et al.: "A Survey on Inference Optimization Techniques for Mixture of Experts Models" - https://arxiv.org/abs/2412.14219
- Sun et al.: "LLM-based Multi-Agent Reinforcement Learning" - https://arxiv.org/abs/2405.11106
- Schick et al.: "Toolformer" - https://arxiv.org/abs/2302.04761
- Hong et al.: "MetaGPT" - https://arxiv.org/abs/2308.00352
- Zhuge et al.: "GPTSwarm" - https://arxiv.org/abs/2402.16823
- Chen, Zaharia, Zou: "FrugalGPT" - https://arxiv.org/abs/2305.05176
- AgentBench - https://arxiv.org/abs/2308.03688
- MASLab - https://arxiv.org/abs/2505.16988
- Model Context Protocol - https://en.wikipedia.org/wiki/Model_Context_Protocol
- NVIDIA / Hugging Face: "Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents" - https://huggingface.co/blog/nvidia/nemotron-3-nano-omni-multimodal-intelligence
- NVIDIA Nemotron 3 Nano Omni technical report - https://arxiv.org/abs/2604.24954





