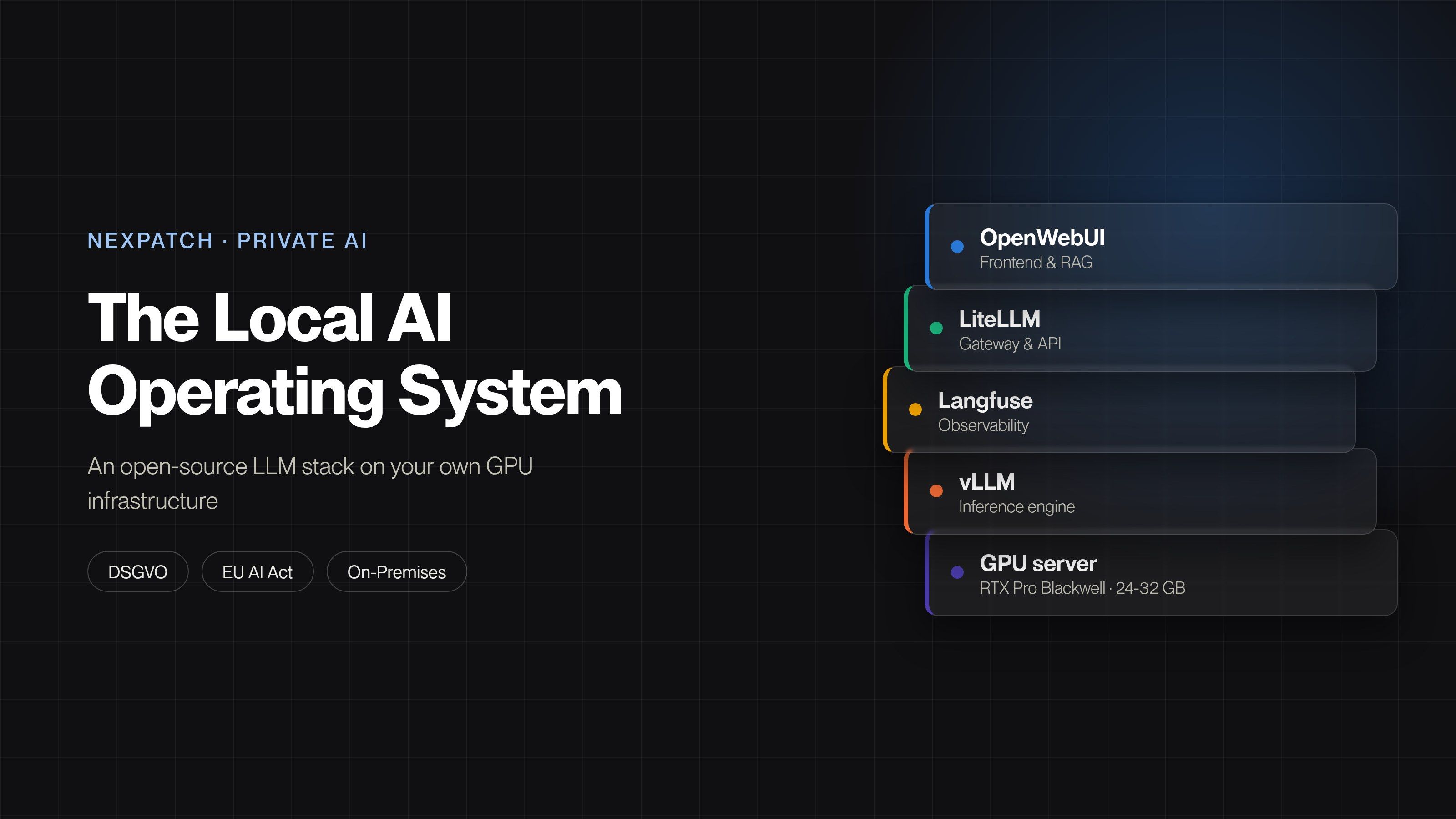
ETL Pipelines Reimagined: Visual Pipeline Orchestration with Orpheon
Data pipelines are broken — not because data has stopped flowing, but because the tools for managing them haven't kept pace with modern requirements. Manual ETL maintenance still consumes 60–80% of data engineering time, while organizations lose an average of $15 million per year to data downtime. The ETL market, now valued at $8.85 billion and growing at nearly 16% CAGR, reveals a paradox: massive investment alongside persistent frustration. Visual pipeline orchestration points the clearest way forward — reducing the complexity of modern data workflows to intuitive drag-and-drop interfaces without sacrificing the power engineers need. Orpheon, a data intelligence platform by NexPatch, stands at the forefront of this shift, combining a visual pipeline builder with native support for Apache Parquet, DuckDB, real-time and batch processing, and integrated data observability. This is ETL reimagined.
The ETL Landscape Is Fracturing, and ELT Is Pouring In

The ETL-versus-ELT debate that dominated data engineering discussions for a decade has found a quiet resolution: The answer is "both." ELT has become the standard for cloud-native analytics workflows, driven by the raw compute power of Snowflake, BigQuery, and Databricks. Classic ETL retains its place in compliance-heavy environments — HIPAA, GDPR, SOX — where data must be transformed before reaching a warehouse. But the real story of 2025–2026 is that neither paradigm wins alone. Lakehouse architectures have emerged where both approaches coexist seamlessly.
The departure from legacy tools has been dramatic. Informatica PowerCenter, Talend On-Prem, and SSIS — the workhorses of the 2010s — are giving way to Python-based frameworks that deliver 50–90% shorter development times at significantly lower cost. Cloud-based ETL now accounts for roughly 66.8% of all deployments and is growing at 17.7% annually. Over 72% of US enterprises rely on cloud-based data architectures, and the three dominant cloud warehouses are nearly tied among practitioners: Snowflake at 28% adoption, Databricks at 29%, and BigQuery at 27.6% among Airflow users.
Yet modernization hasn't eliminated the pain. Gartner estimates that poor data quality costs organizations an average of $12.9 million annually. Data governance consistently ranks as the top challenge for analytics leaders. The talent gap is widening — global demand for data engineers is rising from 2.0 to 2.3 million, but supply isn't keeping up. Cross-cloud data transfer costs alone consume 15–25% of analytics budgets.
Three trends are reshaping the terrain. Zero-ETL, championed by AWS and others, embeds transformations directly into the warehouse, eliminating intermediate pipelines for certain workloads. Reverse ETL, which pushes warehouse data back into operational tools, is growing at 26% CAGR — Fivetran's acquisition of Census in 2025 signaled mainstream arrival. And AI-powered transformations have moved from experiment to standard: 78% of organizations use AI in at least one business function, with tools like Matillion's Maia AI assistant generating pipeline code from natural language descriptions.
Why Visual Orchestration Became Inevitable

Against this backdrop, data teams face a structural dilemma. Code-first orchestration tools — Airflow, Dagster, Prefect — offer power and flexibility but erect steep entry barriers. Apache Airflow, the de facto standard with over 80,000 organizations and 31 million monthly downloads, is notoriously difficult to set up and requires deep Python expertise to manage its webserver, scheduler, and database. One Mage AI user put it succinctly: "It took me 3 months to learn Airflow and 3 hours to be productive with Mage."
At the other end, pure no-code ETL tools deliver quick wins that collapse under production load. They suffer from limited transformation capabilities, debugging opacity, lack of version control, scalability limits, and vendor lock-in.
The gap between these poles is precisely the space where visual pipeline orchestration thrives. The concept — sometimes called "code-optional" or "visual-first, code-capable" — combines graphical pipeline design with the ability to drop into code whenever complexity demands it. The numbers support the demand: Gartner predicts that by 2027, 70% of enterprise applications will be built with low-code or no-code frameworks, up from under 25% five years prior. Forrester reports that organizations using such tools have cut deployment times by up to 70%.
This isn't about dumbing down data engineering. It's about recognizing that the most productive architecture combines visual design for workflow structure, monitoring, and collaboration with code-level control for complex transformations and custom logic.
Orpheon Bridges the Gap with a Visual-First Architecture
Orpheon, developed by NexPatch as a comprehensive data intelligence platform, occupies exactly this intersection. The drag-and-drop pipeline builder allows data engineers, analysts, and business stakeholders to design ETL/ELT workflows visually — defining sources, transformations, and destinations by connecting nodes on a canvas rather than writing boilerplate code. But unlike no-code tools that hit a ceiling when requirements grow complex, Orpheon is code-capable at every level. Engineers can open any pipeline node and write custom Python, SQL, or transformation logic directly within the visual interface.
This hybrid approach solves the collaboration problem that plagues most data teams. When a data engineer builds a pipeline in pure Airflow, the resulting DAG (Directed Acyclic Graph) is opaque to the analytics team that depends on it. When a business analyst creates a workflow in a no-code tool, the engineering team can't integrate it into production CI/CD processes. Orpheon's visual canvas serves as a shared representation that both sides can read, discuss, and modify — each at their appropriate level of abstraction.
What distinguishes Orpheon from other visually capable tools is its native integration of modern data formats and engines. The platform offers first-class support for Apache Parquet and DuckDB, two technologies that have fundamentally changed how data teams think about storage and computation. Instead of routing data through heavyweight external systems, Orpheon can leverage DuckDB's in-process analytics engine for fast, local transformations on Parquet files — an architecture that eliminates round-trips to cloud warehouses for many common operations, drastically reducing both latency and cost.
Orpheon also addresses the batch-versus-streaming question head-on, supporting both real-time and batch processing within a unified framework. Rather than forcing teams to maintain separate pipelines for different latency requirements, the platform allows engineers to design workflows that operate in either mode — or both simultaneously.
Integrated data observability rounds out the platform's capabilities. Instead of bolting on a separate monitoring tool after the fact, Orpheon embeds quality monitoring, lineage tracking, and anomaly detection directly into the pipeline orchestration layer.
Parquet and DuckDB Are Rewriting the Performance Playbook

Orpheon's architectural bet on Parquet and DuckDB mirrors one of the most consequential shifts in modern data infrastructure. Apache Parquet, developed in 2013 by Twitter and Cloudera, has become the undisputed standard columnar format for analytics. Its columnar compression routinely reduces storage requirements by a third or more compared to CSV — DuckDB's own benchmarks show a compression ratio of 12x (1.4 GB CSV to 118 MB Parquet). Every major query engine reads Parquet natively: Spark, Hive, Presto, Athena, BigQuery, Redshift Spectrum, and Snowflake. And Parquet serves as the immutable storage layer for lakehouse frameworks like Apache Iceberg, Delta Lake, and Apache Hudi.
DuckDB's rise has been even more rapid. The in-process OLAP database — often called "SQLite for Analytics" — reached 30,000 GitHub stars in June 2025, with 20 million monthly PyPI downloads, 3 million monthly website visitors, and the fastest growth of any relational system in the DB-Engines Top 50. Its vectorized execution engine processes data in column-oriented batches across all available CPU cores, with automatic spill-to-disk for datasets larger than RAM. Benchmarks tell a compelling story: DuckDB runs up to 100x faster than Spark for local Parquet processing, and analytical queries can execute 100 to 1,000 times faster than identical queries on SQLite or PostgreSQL.
The practical implication for pipeline orchestration is profound. A platform like Orpheon that natively uses Parquet and DuckDB can perform transformations that previously required a cloud warehouse — aggregations, joins, window functions, statistical calculations — entirely within the pipeline engine itself. For datasets under 50 GB, "this approach often wins outright — no network, no cluster spin-up." DuckLake, released in May 2025, extends this with full ACID compliance, time-travel queries, and Iceberg interoperability.
This isn't about replacing Snowflake or Databricks. It's about having the right engine for every step. Orpheon's ability to route transformations to DuckDB for local operations or to external warehouses for heavy loads — all within the same visual pipeline — represents a genuinely efficient architecture.
Real-Time and Batch Processing Converge into a Single Paradigm
The long-standing separation between batch and streaming data processing is dissolving. Research from 2025 summarized the evolution: "The future of cloud ETL lies in convergence." Organizations with unified architectures report 50% cost savings compared to maintaining dual batch and streaming systems.
The Kappa architecture — Jay Kreps' 2014 proposal to eliminate the batch layer entirely by treating all data as a stream — has become the standard for modern data systems, deployed at Uber, Shopify, Twitter, and Disney. Apache Flink has established itself as the leading stream processing framework, capable of handling millions of transactions per second. Spark Structured Streaming's new real-time mode, announced at Databricks DAIS 2025, achieves a P99 end-to-end latency of just 15 milliseconds.
For most organizations, however, the practical middle ground lies in micro-batch processing: small periodic batches that balance latency against fault tolerance and cost. This is exactly the flexibility Orpheon provides. The pipeline builder allows teams to configure individual pipeline stages for batch, micro-batch, or real-time execution based on data source characteristics and business requirements. A single Orpheon pipeline can ingest event data in real time from a streaming source, buffer it in Parquet format, run DuckDB transformations at micro-batch intervals, and load results into a warehouse on a daily schedule — all visually orchestrated with clear dependency management.
Event-driven pipelines represent the most sophisticated expression of this convergence. Instead of relying on fixed schedules, these pipelines trigger actions when new data arrives or specific conditions are met. Orpheon's visual approach makes event triggers, conditional logic, and branching paths visible and configurable on the pipeline canvas.
Data Observability Must Be Built In, Not Bolted On
Pipeline reliability depends on knowing not just that a pipeline ran, but that the data it produced is correct. Data professionals currently spend nearly 40% of their time fixing data issues — chasing broken pipelines, resolving errors, and explaining strange dashboard numbers. Fivetran's Enterprise Benchmark Report 2026, surveying over 500 senior data leaders, found that legacy pipeline approaches have 30–47% higher failure rates, translating to roughly 60 hours of monthly downtime. The business impact is enormous: downtime costs an average of $49,600 per hour, rising to $75,200 in larger enterprises.
The data observability market has responded with a wave of tools. Monte Carlo, the number-one platform on G2 for eight consecutive quarters, uses machine learning to automatically detect anomalies in freshness, volume, schema, and distribution. Great Expectations (GX), the leading open-source framework, lets teams define "expectations" — essentially unit tests for data. The enterprise data observability software market is projected to grow from $1.5 billion in 2025 to $3.76 billion by 2036.
The fundamental problem with standalone observability tools, however, is integration overhead. When monitoring lives in a separate system from orchestration, the feedback loop between detection and remediation requires context-switching between tools. Organizations with automated pipeline observability experience a 73% reduction in mean time to resolution and identify 89% of data quality issues before they impact downstream systems.
Orpheon's approach — embedding observability directly into the orchestration layer — eliminates this gap. Data quality checks, freshness monitoring, schema validation, and anomaly detection are configured as part of the pipeline design, visible on the same canvas as the transformations they protect. Lineage tracking is automatic: because the platform orchestrates the entire workflow, it inherently knows where every piece of data came from and what transformations it underwent.
Production-Ready Pipelines Require More Than Good Tooling
Building a pipeline is one thing. Running it reliably in production is another entirely. Scalability, fault tolerance, CI/CD integration, version control, and testing strategies separate prototype pipelines from production infrastructure.
Modern scalability requires horizontal scaling, distributed processing, and workload balancing. Fault tolerance needs idempotent operations, automated rollback capabilities, and circuit breakers. Self-healing approaches — where automated recovery mechanisms detect failures, diagnose root causes, and apply fixes — reduce mean time to resolution by 72.8%, from 6.9 hours down to an average of 1.88 hours.
CI/CD for data pipelines adapts software engineering practices to data contexts: version-controlling pipeline code alongside schema definitions, embedding data quality gates in deployment pipelines, ensuring environment parity between development and production, and implementing progressive deployment strategies like blue-green releases for pipeline changes.
Version control for visual pipelines presents a particular challenge. Code-first tools integrate naturally with Git because pipelines are text files. Visual tools must serialize their canvas representations — typically as YAML or JSON. Orpheon addresses this by managing pipeline definitions in version-controllable formats beneath the visual layer, enabling standard Git workflows, branching, and pull request reviews while preserving the visual editing experience.
Testing strategies for data pipelines follow a pyramid model:
- Unit tests validate individual transformations (column expectations, type checks, value ranges)
- Integration tests verify end-to-end pipeline execution across components
- Data quality tests monitor schema validation, freshness, volume anomalies, and distribution drift
- Regression tests compare outputs before and after changes using data diffing techniques
The 1-10-100 rule quantifies why this matters: fixing a data quality issue costs $1 at the point of entry, $10 in retrospective cleanup, and $100 once it has propagated downstream. Observability and testing, integrated directly into the orchestration platform — as Orpheon implements it — catch problems at the $1 stage.
How Orpheon Positions Itself in the Orchestration Landscape

The pipeline orchestration market has strong incumbents. Apache Airflow dominates with over 80,000 organizations, a massive ecosystem of 123 provider packages, and the significant Airflow 3.0 release. Dagster offers a compelling asset-centric model with superior built-in lineage and observability. Prefect delivers the fastest developer iteration for cloud-native teams. dbt has become the industry standard for the transformation layer with 44% adoption among Airflow users. Fivetran and Airbyte handle automated data ingestion with hundreds of pre-built connectors.
Each tool, however, leaves significant gaps. Airflow's web UI is frequently criticized as outdated, and its learning curve can consume months of onboarding time. Dagster's asset model, while powerful, adds conceptual overhead. Prefect's smaller ecosystem limits enterprise integration options. dbt handles only the transformation layer — it requires separate tools for ingestion and orchestration.
Orpheon's value proposition spans multiple of these gaps simultaneously. The visual-first interface achieves what Airflow's UI cannot: making pipeline design accessible to non-engineers while remaining powerful enough for production workloads. Native Parquet and DuckDB support provides transformation capabilities that dbt and Fivetran must deliver through external systems. Unified batch and real-time processing eliminates the need to maintain separate streaming infrastructure alongside batch orchestration. And embedded observability addresses the monitoring gap that forces most teams to integrate standalone tools as separate systems.
The comparison isn't aimed at suggesting Orpheon fully replaces these tools. Rather, Orpheon occupies a space that none of the incumbents fully serve: a unified, visual platform for ingestion, transformation, orchestration, and observability across batch and real-time workloads, with modern format support (Parquet, DuckDB) and a code-optional interface that serves both engineers and analysts.
The Future Belongs to Platforms That Think in Data, Not Tasks
The data engineering landscape is converging on several unmistakable trajectories in 2026 and beyond. AI-powered pipeline building has evolved from novelty to necessity — Gartner predicts that by 2027, AI-augmented workflows will reduce manual data management effort by nearly 60%, and over 80% of organizations will deploy generative AI copilots by 2026. Databricks reports that more than 80% of new databases on the platform are now launched by AI agents rather than human engineers.
Self-healing pipelines, where automated systems detect failures, diagnose root causes, and apply fixes without human intervention, are advancing from research concept to production reality. The semantic layer — the curated business logic that gives raw data meaning — has been elevated by Gartner to "essential infrastructure."
Data engineering roles themselves are transforming. Joe Reis's 2026 survey of over 1,100 practitioners found that 82% use AI daily, but 64% remain stuck in the experimentation phase. His blunt forecast: "2026 will see more data teams dissolved, merged with engineering, or outsourced. The teams that survive will be those that have demonstrated business value." Indeed Hiring Labs 2026 data shows that job postings for data & analytics have declined 15.2% year over year.
In this environment, the tools that survive will be those that amplify human judgment rather than demand human labor. Visual pipeline orchestration isn't just a convenience — it's an architectural response to the reality that data engineering must become faster, more collaborative, and more accessible without sacrificing reliability. Orpheon's approach — visual-first design, code-optional depth, native modern format support, unified processing paradigms, and embedded observability — positions it as a platform built for this new era, rather than adapted from the previous one.
The ~$9 billion ETL market is heading toward $21 billion by 2031. The data observability market will more than double. Global data generation will surpass the 221-zettabyte mark in 2026. The organizations that successfully navigate this growth won't be those with the most complex pipelines. They'll be the ones whose pipelines are visible, understandable, and reliable — designed by humans and machines working together on a shared canvas. That's the future Orpheon is building toward, and it's a future the entire data engineering community needs.