Time Series Forecasting mit PatchTST: Warum klassische Modelle nicht mehr reichen
Zeitreihenprognosen sind in vielen Unternehmen noch immer ein Patchwork aus getrennten Werkzeugen. Daten werden in einer ETL-Pipeline vorbereitet, Features entstehen in Notebooks, Modelle werden in einem separaten Training-Job versioniert, und Forecasts landen später als CSV, Dashboard oder lose API in operativen Systemen. Technisch funktioniert das oft. Wissenschaftlich und betrieblich ist es aber fragil: Schon kleine Änderungen in Sampling-Rate, Missing-Value-Strategie, Feature-Lags oder Backtest-Schnitt können die gemessene Modellgüte stark verschieben.
Gerade bei dynamischen Märkten, volatilen Lieferketten, Energiepreisen, Produktionslasten oder Finanzsignalen reicht ein isoliertes Forecasting-Modell nicht mehr aus. Moderne Prognosesysteme müssen Datenqualität, Feature Engineering, Modelltraining, Evaluation, Monitoring und Auslieferung gemeinsam denken. Genau an dieser Stelle setzt der NexPatch-Ansatz mit Orpheon an: Forecasting wird kein Notebook-Ergebnis, sondern ein reproduzierbarer Plattformprozess.
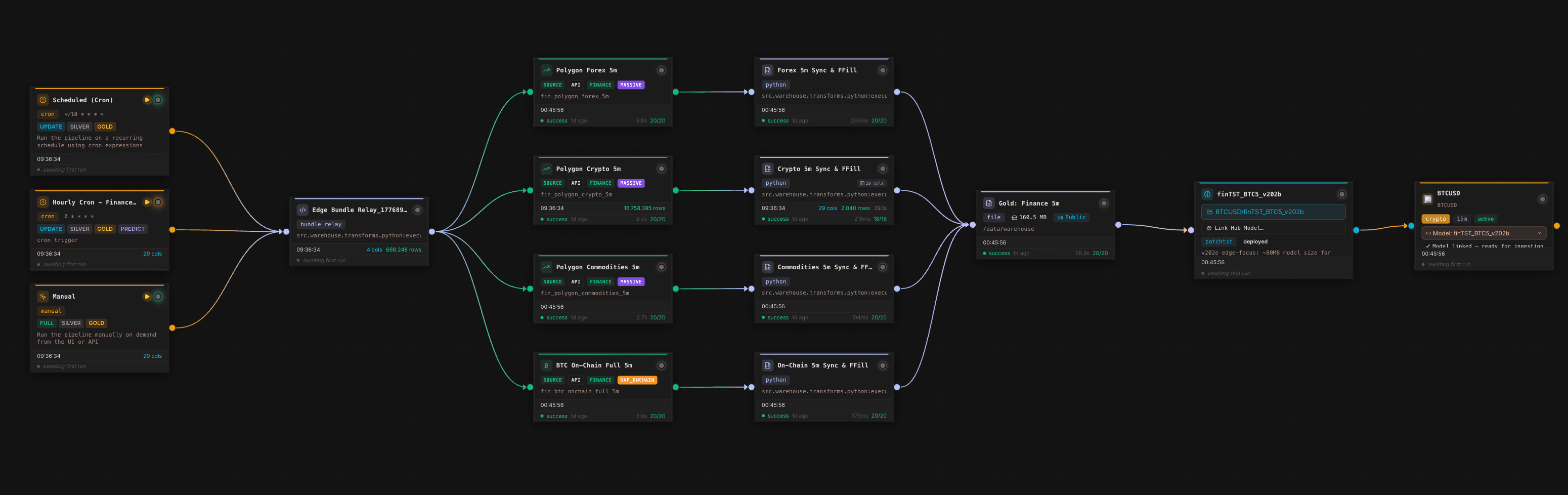
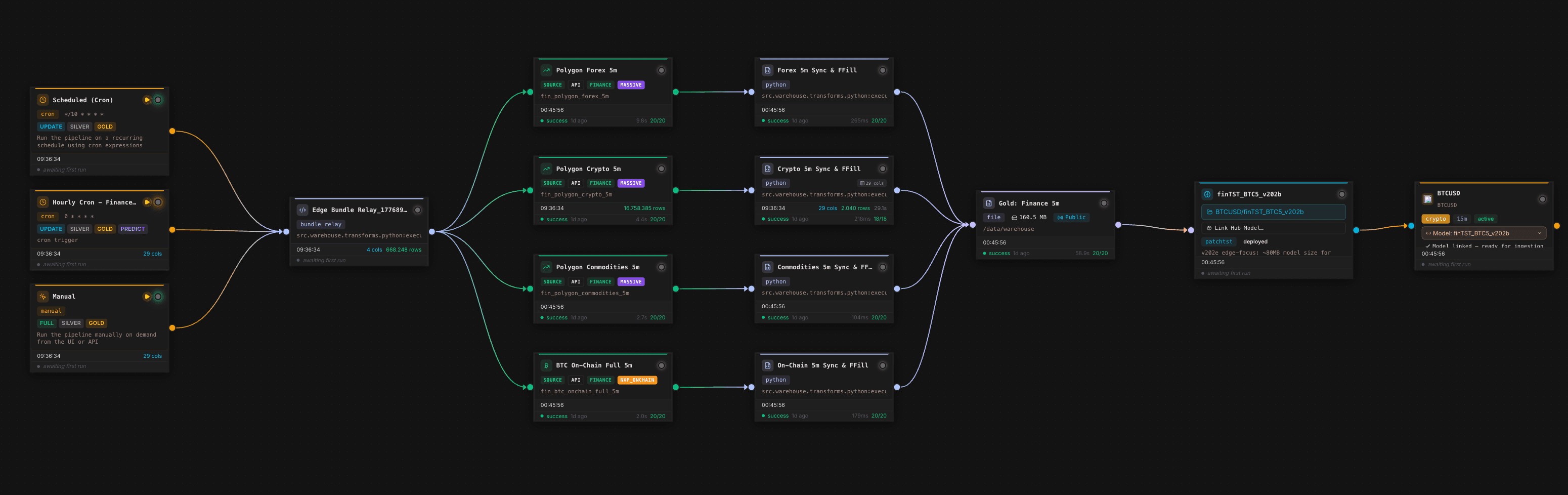
Der Canvas zeigt den operativen Kern: Scheduler und manuelle Trigger starten denselben Datenfluss, mehrere Finanz- und On-Chain-Quellen werden synchronisiert, Transformationsknoten harmonisieren die Daten auf ein 5-Minuten-Raster, ein Gold-Layer-Knoten schreibt die trainierbare Tabelle, und ein Modellknoten bindet das Forecasting-Modell als nachgelagertes Datenprodukt an. Für Forecasting ist das entscheidend, weil Modellqualität nicht nur aus der Architektur entsteht, sondern aus der Wiederholbarkeit der gesamten Datenkette.
Warum ARIMA und Prophet nicht verschwinden, aber nicht mehr genügen
ARIMA, SARIMA, exponentielle Glättung und Prophet sind weiterhin nützlich. Sie sind interpretierbar, schnell aufzusetzen und für viele univariate Zeitreihen mit stabilen saisonalen Mustern ausreichend. Ein klassisches Beispiel ist eine einzelne Absatzreihe mit Wochen- und Jahressaisonalität, begrenzten Ausreißern und wenig externen Einflussgrößen.
Das Problem beginnt, sobald die Prognoseumgebung realer wird:
- Mehrere Assets, Produktlinien oder Sensoren beeinflussen sich gegenseitig.
- Externe Variablen wirken zeitverzögert auf die Zielgrösse.
- Signale sind nicht stationär, sondern wechseln ihr Regime.
- Der Prognosehorizont ist lang genug, dass lokale Muster und langfristiger Kontext gleichzeitig relevant werden.
- Daten kommen kontinuierlich aus APIs, Warehouses, Dateien oder operativen Systemen.
Klassische Modelle können solche Situationen teilweise abbilden, aber oft nur mit viel manueller Feature-Arbeit. Für Data Scientists bedeutet das: Lags bauen, exogene Variablen pflegen, Missing Values behandeln, Modelle je Serie tunen, Backtests separat verwalten und Deployment-Lösungen nachziehen. Der Engpass ist dann nicht nur die Modellgenauigkeit. Der Engpass ist die gesamte Toolchain.
PatchTST: Patches statt einzelne Zeitschritte
PatchTST hat die Diskussion um Long-Term Time Series Forecasting verändert, weil das Modell Zeitreihen nicht mehr Schritt für Schritt als einzelne Token behandelt. Stattdessen werden historische Sequenzen in überlappende Zeitfenster zerlegt. Diese Patches enthalten lokale Muster, reduzieren die effektive Sequenzlänge und machen Transformer-Architekturen für lange Horizonte effizienter.
Der Kernvorteil liegt darin, dass ein Modell nicht jeden einzelnen Messpunkt isoliert verarbeiten muss. Ein Patch kann zum Beispiel die letzten 16 oder 32 Messpunkte eines Signals zusammenfassen. Damit sieht das Modell kurzfristige Bewegung, lokale Volatilität, Ausreißer und Trendwechsel in einem kompakteren Kontext. Gegenüber früheren Transformer-Varianten reduziert Patch-basierte Tokenisierung den Aufwand für lange Sequenzen und kann die Lernaufgabe stabilisieren.
In NexPatch-Projekten nutzen wir diese Idee nicht als reine Paper-Implementierung, sondern als produktionsorientierte Topologie für multivariate Forecasting-Systeme. Wichtig ist eine fachliche Präzisierung: Unser Ansatz ist nicht darauf reduziert, Kanäle strikt unabhängig voneinander zu behandeln. Entscheidend ist, dass das Modell Korrelationen über Zeit und Assets hinweg erkennt.
Das betrifft insbesondere:
- Lag Features: Welche Signale führen oder folgen der Zielreihe mit zeitlichem Abstand?
- Cross-Lag-Beziehungen: Bewegt Asset A heute Asset B in 15, 60 oder 240 Minuten?
- Inter-Feature-Korrelationen: Welche Kombinationen aus Preis, Volumen, Kalender, Makro-, On-Chain- oder Betriebsdaten erklären ein zukünftiges Verhalten?
- Regime-Wechsel: Wann verändern sich Korrelationen, etwa bei Marktereignissen, Kampagnen, Lastspitzen oder saisonalen Umbrüchen?
Damit unterscheidet sich der produktive NexPatch-Winkel von einer rein channel-independent Lesart. Die Architektur soll nicht nur lokale Sequenzmuster finden, sondern auch zeitlich versetzte und asset-übergreifende Zusammenhänge nutzbar machen.
Wissenschaftliche Einordnung: Was moderne Benchmarks wirklich messen
Zeitreihen-Benchmarks sind empfindlich. Ein Vergleich zwischen ARIMA, Prophet, Gradient Boosting, N-BEATS, Temporal Fusion Transformer oder PatchTST ist nur aussagekräftig, wenn Daten-Splits, Forecast-Horizon, Feature-Verfügbarkeit und Fehlermetriken sauber definiert sind. Die Literatur zeigt drei wiederkehrende Punkte:
- Long-Horizon Forecasting bevorzugt Modelle, die Kontext effizient verdichten. PatchTST adressiert genau diese Herausforderung, indem es Patches als Token nutzt und lange historische Fenster handhabbarer macht.
- Multivariate Forecasts brauchen klare Feature-Zeitpunkte. Exogene Variablen dürfen im Backtest nur so verwendet werden, wie sie im realen Betrieb zum Forecast-Zeitpunkt verfügbar wären. Sonst entsteht Leakage.
- Eine einzelne Metrik reicht selten aus. MAE und RMSE bewerten absolute Fehler, MAPE kann bei kleinen Zielwerten instabil sein, sMAPE ist robuster, und quantile losses sind wichtig, wenn Unsicherheit oder Risikoasymmetrie zählen.
Für NexPatch ist deshalb nicht die Behauptung "Transformer ist besser" entscheidend, sondern ein reproduzierbares Evaluationsdesign: rolling-origin backtesting, feste Baselines, identische Datenfenster, dokumentierte Feature-Lags, getrennte Validierungs- und Testbereiche sowie eine Betriebsmetrik, die zur Entscheidung passt.
Feature Engineering als Teil des Modellsystems
Viele Forecasting-Initiativen scheitern nicht am ersten Modell. Sie scheitern am zweiten, dritten und zehnten Produktionslauf. Sobald ein Modell regelmäßig laufen soll, braucht das Team mehr als Trainingscode:
- Datenquellen müssen stabil angebunden werden.
- Rohdaten brauchen Validierung, Normalisierung und Historisierung.
- Features müssen reproduzierbar entstehen.
- Backtests müssen gegen feste Baselines laufen.
- Modelle müssen versioniert und überwacht werden.
- Forecasts müssen in operative Systeme gelangen.
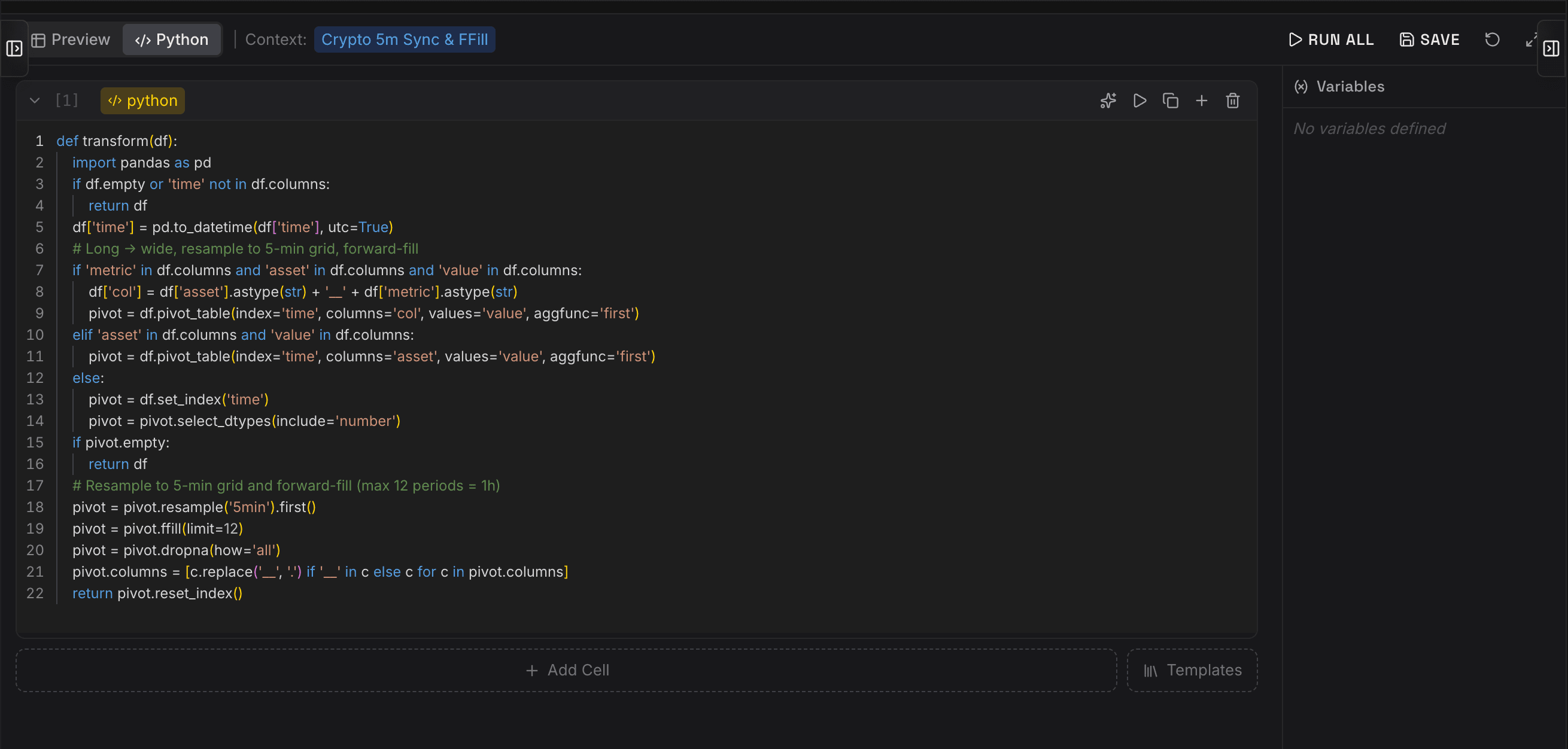
Der Editor-Screenshot zeigt ein typisches Beispiel: Rohdaten werden nach time, asset, metric und value pivotiert, auf ein 5-Minuten-Raster resampelt und nur begrenzt forward-filled. Diese Details wirken klein, sind aber wissenschaftlich relevant. Ein zu aggressiver Forward-Fill kann künstliche Stabilität erzeugen; ein falsch gesetztes Resampling kann Lags verschieben; ein inkonsistenter Pivot kann Features zwischen Assets vermischen. Orpheon macht diese Logik explizit, versionierbar und im Pipeline-Kontext ausführbar.
Orpheon als Forecasting-Lifecycle, nicht nur als ETL-Tool
Die Besonderheit des NexPatch-Systems liegt im Zusammenspiel aus Datenplattform und Modelltopologie. Orpheon behandelt Forecasting nicht als isolierten ML-Job, sondern als Datenprodukt mit Lifecycle.
Ein typischer Forecasting-Flow sieht so aus:
- Ingestion: APIs, Dateien, Warehouses oder Streaming-nahe Quellen werden angebunden.
- Transformation: Python- oder SQL-Logik bereinigt Daten, resampelt Zeitreihen, erzeugt Lags, füllt Lücken und baut Cross-Asset-Features.
- Gold Layer: Eine konsistente Feature-Tabelle wird als trainierbare Grundlage gespeichert.
- Training: Patch-basierte Transformer-Modelle werden auf definierten Horizons, Backtest-Fenstern und Baselines trainiert.
- Evaluation: Fehlermaße, Drift, Datenqualität und Laufhistorie werden sichtbar gemacht.
- Forecast API: Prognosen werden nicht exportiert, sondern als API-fähiges Datenprodukt ausgeliefert.
Das ist der entscheidende Unterschied: Das Modell lebt nicht neben der Plattform, sondern in ihr. Forecasts werden dadurch wiederholbar, versionierbar und anschlussfähig für Anwendungen, Dashboards, Agents oder operative Workflows.
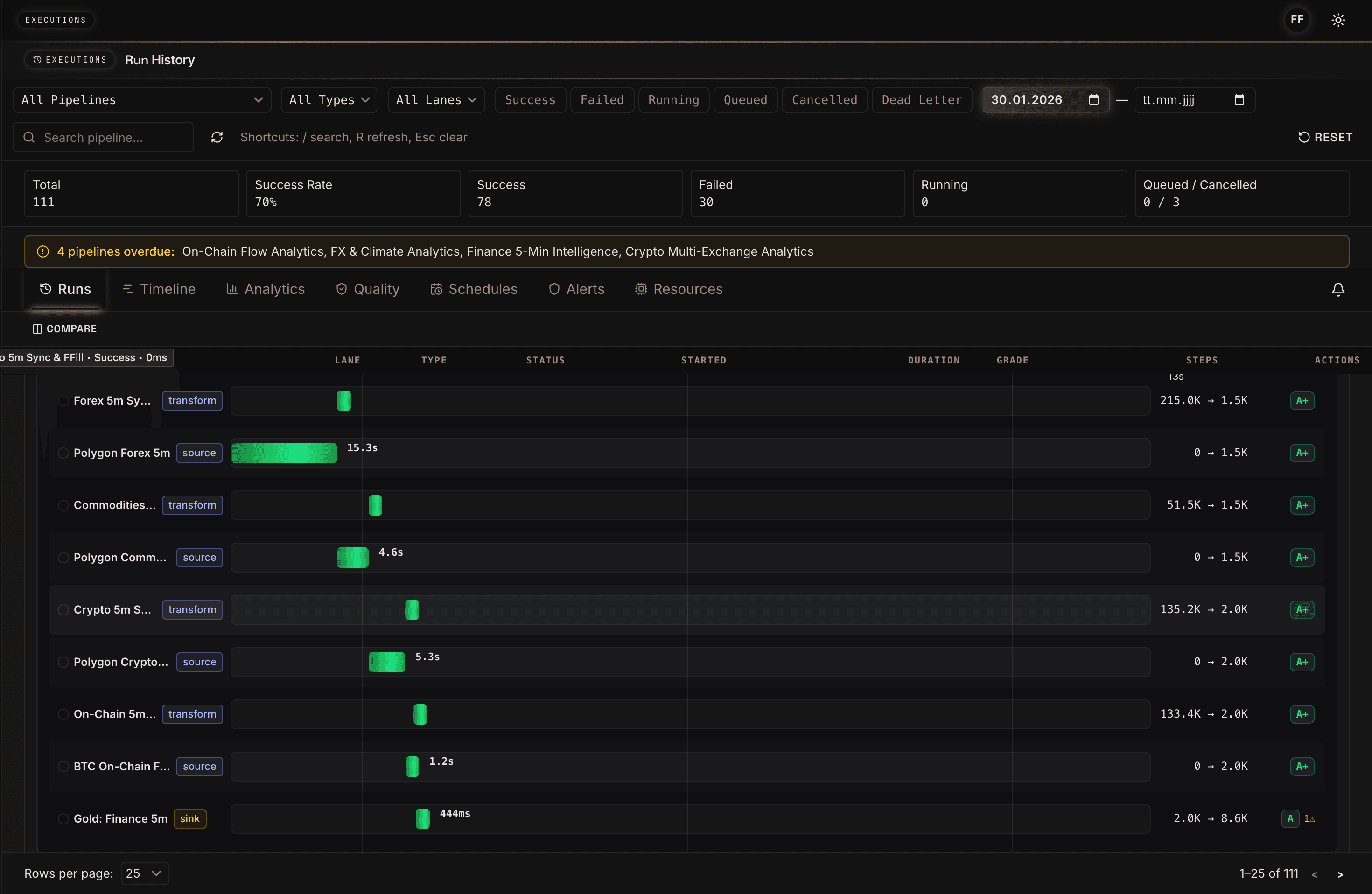
Die Execution-Ansicht zeigt, wie Orpheon einzelne Pipeline-Schritte nicht nur ausführt, sondern beobachtbar macht: Quellen, Transformationen und Sink-Schritte erhalten Laufzeiten, Status, Datenmengen und Qualitätsnoten. Für Forecasting ist das mehr als DevOps-Komfort. Es ist die Grundlage, um Trainingsdaten und spätere Prognosen zu auditieren: Welche Quelle war langsam? Welche Transformation reduzierte die Zeilenzahl? Welcher Lauf erzeugte den Gold Layer, auf dem das Modell trainiert wurde?
Warum Lag- und Inter-Feature-Korrelationen so wichtig sind
In realen Forecasting-Szenarien ist die Zielzeitreihe selten allein erklärbar. Ein Absatzsignal kann von Kampagnen, Wetter, Lagerbestand und Preisaktionen beeinflusst werden. Ein Energiesignal hängt von Wetter, Kalender, Lastprofilen und Marktpreisen ab. Ein Finanzsignal kann auf Volumen, Volatilität, verwandte Assets, On-Chain-Metriken oder externe Liquiditätsindikatoren reagieren.
Die entscheidende Frage lautet nicht nur: Was ist in der Zielreihe passiert? Sondern: Welche Signale haben vorher etwas angezeigt?
Genau hier werden Lag Features und Inter-Feature-Korrelationen relevant. Ein Modell muss erkennen, dass ein Signal nicht gleichzeitig wirken muss. Es kann führen, nachlaufen, nur in bestimmten Regimen relevant sein oder sich mit anderen Features gegenseitig verstärken. Eine moderne PatchTST-Topologie kann solche Muster über historische Fenster und Feature-Gruppen hinweg lernen, während die Plattform sicherstellt, dass diese Features konsistent berechnet und überwacht werden.
15-30 Prozent bessere Forecasts: Wie man die Zahl sauber liest
Die Angabe von 15-30 Prozent Genauigkeitsverbesserung ist kein universelles Versprechen für jede Datenlage. Sie ist ein realistischer Ziel- und Erfahrungsbereich, wenn ein moderner, patch-basierter Transformer gegen klassische Baselines wie ARIMA, Prophet, naive saisonale Prognosen oder einfache Gradient-Boosting-Setups evaluiert wird und die Datenbasis ausreichend reichhaltig ist.
Wichtig ist die saubere Trennung:
- Öffentliche PatchTST-Benchmarks zeigen, dass patch-basierte Transformer bei vielen Long-Horizon-Datasets gegen klassische und frühere Transformer-Modelle stark abschneiden.
- Kundenspezifische NexPatch-Evaluierungen müssen immer gegen die konkrete Baseline, den Forecast-Horizon, die Datenqualität und die Kosten des Betriebs bewertet werden.
- Die beste Architektur bringt wenig, wenn die Features instabil sind oder der Produktionspfad Forecasts nicht rechtzeitig ausliefert.
Deshalb startet ein guter Forecasting-Pilot nicht mit einer Modellbehauptung, sondern mit einem Benchmark-Design: Welche Baseline gilt? Welcher Horizon zählt? Welche Fehlermaße sind geschäftsrelevant? Und wie schnell muss der Forecast im Zielsystem verfügbar sein?
Monitoring: Von Modellgüte zu Betriebszuverlässigkeit
Data Scientists denken oft zuerst in MAPE, MAE, RMSE oder quantilen Fehlern. Technische Entscheider fragen zusätzlich: Wie verlässlich läuft das System? Wie gut ist es auditierbar? Wie schnell kann ein neues Asset, Produkt oder Werk angebunden werden? Wie sicher ist der API-Zugriff? Wie viel manuelle Wartung bleibt?
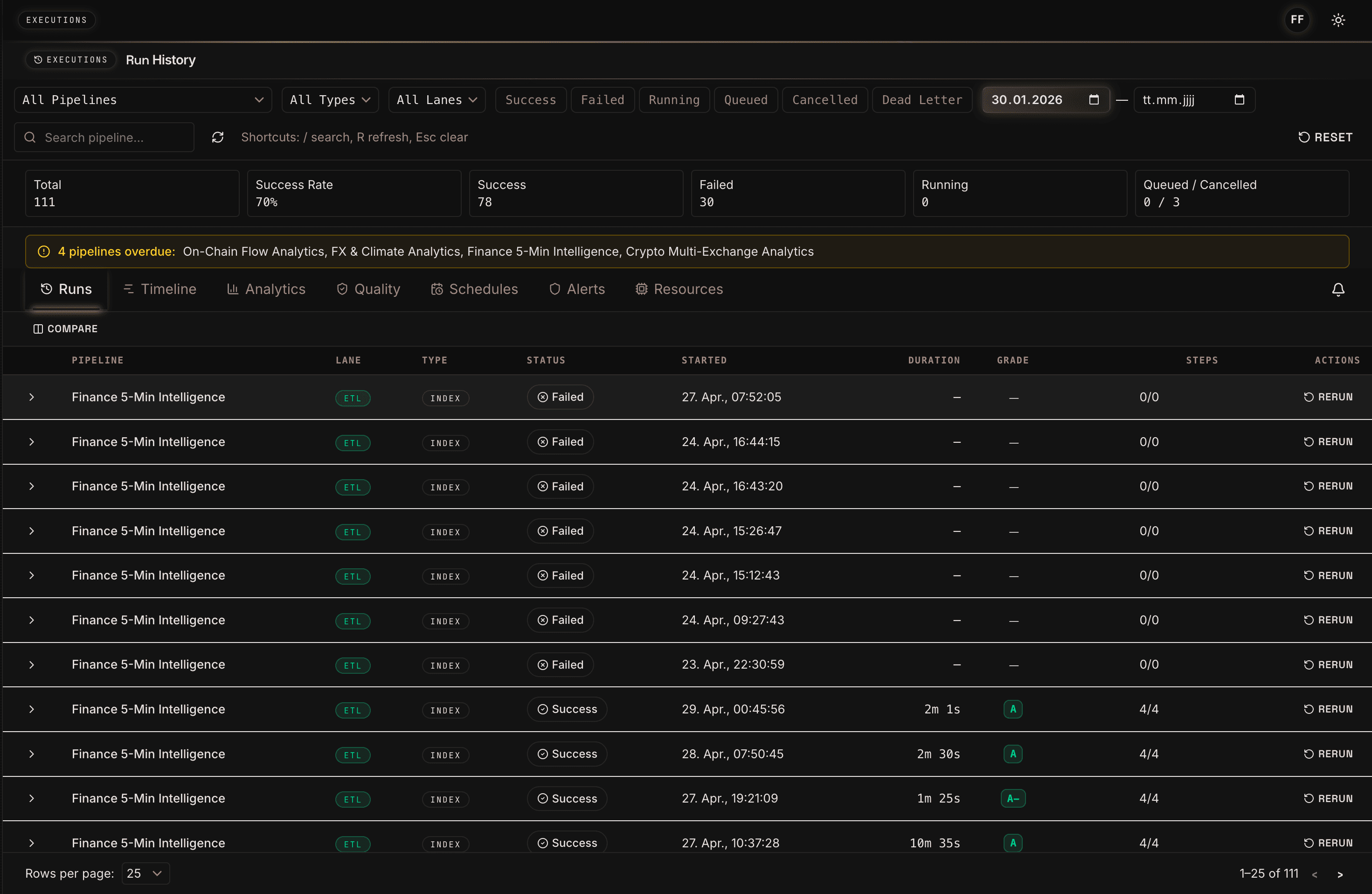
Die Run-History macht sichtbar, dass Forecasting-Systeme nicht nur Modellartefakte sind, sondern wiederkehrende Produktionsprozesse. Erfolgsrate, fehlgeschlagene Läufe, Overdue-Warnungen und Rerun-Aktionen helfen Teams, Datenfrische und Pipeline-Stabilität in die Modellbewertung einzubeziehen. Ein Forecast mit hoher Offline-Accuracy ist wenig wert, wenn der Datenlauf vor dem Marktschluss ausfällt oder der Gold Layer nicht rechtzeitig aktualisiert wird.
Forecasts als API-fähige Datenprodukte
Viele Systeme enden beim Modelltraining. Orpheon geht weiter: Der Gold Layer und die daraus abgeleiteten Forecasts können als kontrollierte Datenprodukte bereitgestellt werden. Das ist besonders relevant, wenn Prognosen nicht nur in einem Dashboard betrachtet, sondern von Agents, Anwendungen, ERP-Systemen, Trading-Engines oder Automatisierungen konsumiert werden.
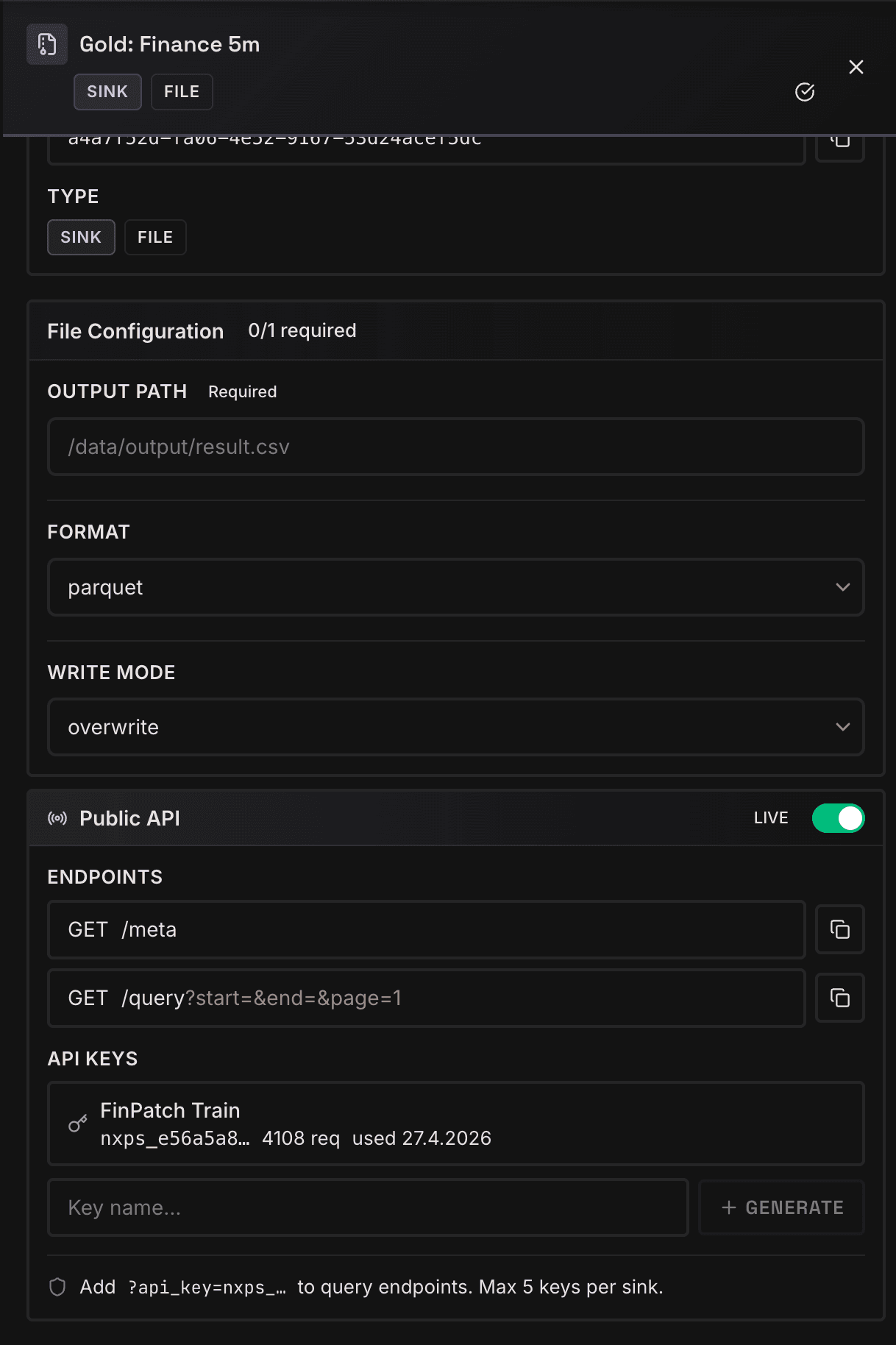
Der Gold-Config-Screenshot zeigt die Brücke zwischen Data Engineering und produktiver Nutzung: Ausgabeformat, Schreibmodus, Public-API-Schalter, Meta- und Query-Endpunkte sowie API Keys werden an derselben Stelle verwaltet. Damit wird Forecasting nicht als Dateiablage gedacht, sondern als abrufbares, abgesichertes und versionierbares Datenprodukt.
Implementierungs-Checkliste für Teams
Wer Time Series Forecasting 2026 ernsthaft produktiv machen will, sollte fünf Fragen beantworten, bevor ein Modell gewählt wird:
- Welche Datenquellen sind stabil genug für Training und Betrieb?
- Welche Lags und externen Features sind fachlich plausibel und zum Forecast-Zeitpunkt verfügbar?
- Welche klassische Baseline ist fair: ARIMA, Prophet, naive saisonale Prognose oder bestehendes internes Modell?
- Welche Metrik entscheidet wirklich: Fehler über alle Zeitpunkte, Fehler an Peaks, Risiko asymmetrischer Fehlentscheidungen oder Kosten im Prozess?
- Wie werden Forecasts ausgeliefert: Dashboard, API, Agent, ERP, Trading-System oder automatisierter Workflow?
Erst danach entscheidet sich, wie komplex die Modelltopologie sein muss. PatchTST ist stark, wenn lange historische Fenster, viele Features, Cross-Asset-Abhängigkeiten und lange Horizonte relevant sind. Für einfache, stabile Einzelserien kann eine klassische Baseline weiterhin die bessere erste Wahl sein.
Fazit
Klassische Forecasting-Modelle reichen nicht mehr aus, wenn Unternehmen nicht nur bessere Prognosen, sondern produktive Forecasting-Systeme brauchen. Patch-basierte Transformer wie PatchTST verbessern die Fähigkeit, lange Kontexte, lokale Muster und zeitlich versetzte Beziehungen zu lernen. Der eigentliche Hebel entsteht aber erst, wenn diese Modelle in eine Plattform eingebettet werden, die ETL, Feature Engineering, Training, Evaluation, Monitoring und Forecast-Auslieferung gemeinsam betreibt.
Der NexPatch-Ansatz mit Orpheon zielt genau darauf: Forecasting wird vom isolierten Modell zum durchgehenden Datenprodukt. Das Modell erkennt Lag Features, Cross-Asset-Abhängigkeiten und Inter-Feature-Korrelationen. Die Plattform sorgt dafür, dass diese Erkenntnisse reproduzierbar trainiert, überwacht und als API-fähige Forecasts nutzbar werden.
Referenzen
- Nie, Y., Nguyen, N. H., Sinthong, P. und Kalagnanam, J. (2023): A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. ICLR 2023. arXiv:2211.14730.
- Lim, B., Arik, S. O., Loeff, N. und Pfister, T. (2021): Temporal Fusion Transformers for Interpretable Multi-horizon Time Series Forecasting. International Journal of Forecasting.
- Oreshkin, B. N., Carpov, D., Chapados, N. und Bengio, Y. (2020): N-BEATS: Neural basis expansion analysis for interpretable time series forecasting. ICLR 2020.
- Taylor, S. J. und Letham, B. (2018): Forecasting at Scale. The American Statistician.
- Box, G. E. P., Jenkins, G. M., Reinsel, G. C. und Ljung, G. M. (2015): Time Series Analysis: Forecasting and Control. Wiley.
- Hyndman, R. J. und Athanasopoulos, G. (2021): Forecasting: Principles and Practice. 3rd edition, OTexts.
- Makridakis, S., Spiliotis, E. und Assimakopoulos, V. (2022): M5 accuracy competition: Results, findings, and conclusions. International Journal of Forecasting.
- Zeng, A., Chen, M., Zhang, L. und Xu, Q. (2023): Are Transformers Effective for Time Series Forecasting? AAAI 2023.
- Wu, H., Xu, J., Wang, J. und Long, M. (2021): Autoformer: Decomposition Transformers with Auto-Correlation for Long-Term Series Forecasting. NeurIPS 2021.
- NexPatch Orpheon: Produktperspektive auf ETL, Feature Engineering, Training, Monitoring und Forecast-Auslieferung als einheitliche Plattform.





