
Private KI-Agenten-Systeme mit orchestrierten, spezialisierten Modellen
Eine Deep-Research-Analyse zur Architektur, Forschung und Praxis. Stand: Mai 2026.
Die letzten 24 Monate haben die Architekturphilosophie generativer KI grundlegend verschoben. 2023 dominierte noch die Idee, dass ein immer größeres monolithisches Modell die Königsdisziplin sei. 2024 bis 2026 hat sich eine andere Logik durchgesetzt: heterogene Agenten-Kollektive, orchestrierende Meta-Agenten und lokal hostbare Small Language Models (SLMs), die Routinearbeit kosteneffizient und datenschutzfreundlich übernehmen.
Der Kern dieser Entwicklung ist einfach: Nicht jede Aufgabe braucht ein 70B- oder Frontier-Modell. In agentischen Systemen entstehen viele repetitive, schmale und schemagebundene Aufrufe: Tool-Calls, Extraktion, Klassifikation, Validierung, Code-Snippets, OCR-Nachbearbeitung, Retrieval und kleine Planungsentscheidungen. Genau hier sind spezialisierte SLMs oft ausreichend, schneller, günstiger und besser kontrollierbar. Das NVIDIA-Positionspapier "Small Language Models are the Future of Agentic AI" fasst es prägnant: SLMs sind für viele Invocations in agentischen Systemen stark genug, geeigneter und ökonomisch notwendig.

Für private, on-premise-fähige KI-Systeme entsteht daraus ein neues Zielbild: ein zentraler Conductor zerlegt Aufgaben, routet sie an spezialisierte Modelle, bindet lokale Daten über MCP an, kontrolliert Kosten und Latenz und führt Ergebnisse unter Guardrails wieder zusammen.
Vom monolithischen Modell zum Agentenkollektiv
Der Unterschied zwischen einem einzelnen Universalmodell und einem orchestrierten Agentensystem ist nicht nur technisch. Er verändert Betrieb, Compliance und Wirtschaftlichkeit.
| Dimension | Monolithisches LLM | Orchestriertes Multi-Agent-System |
|---|---|---|
| Inferenzkosten | Jeder Token aktiviert sehr viele Parameter | SLMs übernehmen Routine, große Modelle nur Edge-Cases |
| Hardware | Meist Cloud-API oder A100/H100-Klasse | RTX-4090, Apple Silicon oder lokale GPU-Workstations für viele Aufgaben |
| Spezialisierung | Generalist mit Prompting | Pro Domäne fine-tunbar mit LoRA/QLoRA |
| Privacy | Daten verlassen häufig die Organisation | Vollständig on-premise oder hybrid möglich |
| Skalierung | Vertikal teuer | Agenten und Modelle horizontal skalierbar |
| Wartbarkeit | Verhalten steckt im Gesamtmodell | Einzelne Submodelle, Tools und Policies separat austauschbar |
Das Muster erinnert an Mixture-of-Experts (MoE). MoE aktiviert innerhalb eines Modells nur ausgewählte Experten pro Token. Multi-Agent-Systeme tun dasselbe makroskopisch: Sie aktivieren nur die Fähigkeiten, die eine Aufgabe wirklich braucht. Konzepte wie Top-k-Routing, Capacity Factor, Load Balancing und Sparse Activation wandern damit aus der Modellarchitektur in die Systemarchitektur.
Wissenschaftliche Grundlagen
Mixture-of-Experts als Vorbild
Die MoE-Idee geht auf Jacobs et al. zurück und wurde mit Switch Transformer, Mixtral und DeepSeek-V3 popularisiert. Ein Gating-Netzwerk entscheidet, welche Experten für einen Token aktiviert werden. Moderne Surveys zu MoE-Inferenzoptimierung zeigen, dass effizientes Routing Rechenaufwand um 30 bis 50 Prozent senken kann, während Hardware-Optimierungen weitere 2- bis 4-fache Beschleunigung bringen.
Für Agenten bedeutet das: Routing ist kein Nebenthema, sondern die zentrale Effizienzschicht. Ein privates Agentensystem muss entscheiden, wann ein 7B-Tool-Caller reicht, wann ein 14B-Planer gebraucht wird und wann ein 70B-Modell die Mehrkosten rechtfertigt.
Multi-Agent Reinforcement Learning trifft LLMs
LLM-basierte Multi-Agent-Reinforcement-Learning-Forschung untersucht, wie Modelle als Koordinatoren, Kritiker oder Sprecher in kooperativen Settings eingesetzt werden. Verfahren wie Criticize-Reflect oder MAGRPO zeigen, dass kollaborative Code- und Schreibaufgaben durch trainierte Multi-Agenten besser gelöst werden können als durch Single-Agent-Setups.
Besonders wichtig für Unternehmen ist die Router-Forschung. xRouter, HierRouter und RL-Conductor modellieren Delegation als Entscheidung unter Kosten, Qualität und Latenz. Die Erkenntnis: End-to-end trainierte Router treffen bessere kontextsensitive Entscheidungen als starre Heuristiken. Das Risiko ist Routing Collapse: Der Router nutzt zu oft das stärkste Modell. Cost-Aware-Reward-Shaping und Skill-Orchestrierung sollen genau das verhindern.
Tool-augmented Agents
Toolformer hat gezeigt, dass LLMs externe APIs durch selbstüberwachtes Training nutzen können. Darauf folgten ReAct, ToolLLM, ToolAlpaca, ToolMaker und Tool-MVR. Der Trend ist klar: Agenten werden weniger wertvoll, wenn sie nur Text generieren, und deutlich wertvoller, wenn sie Datenbanken, Code, Dateien, Suchindizes und interne APIs sicher bedienen können.
Für private Systeme heißt das: Tool-Calling muss standardisiert, beobachtbar und eingeschränkt sein. Ein lokaler Postgres-MCP-Server, ein Filesystem-MCP-Server und ein Git-MCP-Server sind keine Komfortfunktionen, sondern die Arbeitsarme des Agentensystems.
NVIDIA Nemotron 3 Nano Omni als neuer Baustein
NVIDIA Nemotron 3 Nano Omni ist ein gutes Beispiel dafür, wie schnell sich die Rolle spezialisierter Modelle in privaten Agentensystemen verändert. Das Modell ist nicht nur ein Vision-Language-Modell, sondern ein omni-modaler Baustein für Dokumente, Bilder, Audio, Video und GUI-Agenten. Laut NVIDIA/Hugging Face ist es für fünf Workload-Klassen ausgelegt: reale Dokumentenanalyse, automatische Spracherkennung, langes Audio-Video-Verstehen, agentische Computer-Nutzung und allgemeines multimodales Reasoning.
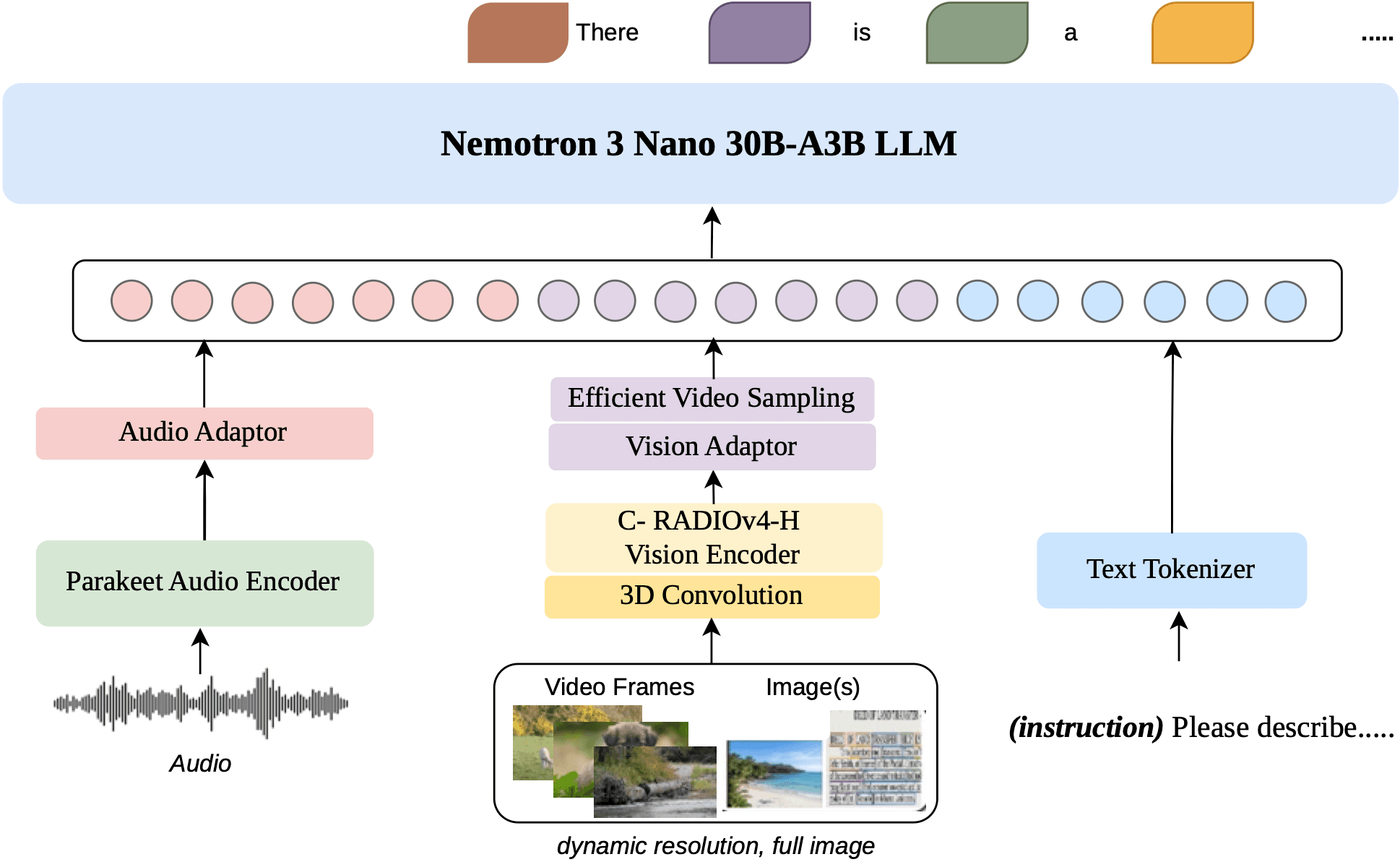
Bildquelle: NVIDIA / Hugging Face, "Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents", Figure 2.
Architektonisch ist Nemotron 3 Nano Omni besonders interessant, weil es mehrere Strömungen bündelt, die auch für private Multi-Agent-Systeme relevant sind. Der Sprach-Backbone Nemotron 3 Nano 30B-A3B kombiniert Mamba-State-Space-Layer, Mixture-of-Experts und Grouped-Query-Attention. Konkret beschreibt NVIDIA 23 Mamba-Layer, 23 MoE-Layer mit 128 Experten und Top-6-Routing sowie 6 GQA-Layer. Für die Modalitäten nutzt das System C-RADIOv4-H als Vision-Encoder und Parakeet-TDT-0.6B-v2 als Audio-Encoder, die über leichte MLP-Projektoren in einen gemeinsamen Tokenraum eingebunden werden.
Für Enterprise-Agenten sind drei Details wichtiger als die reine Modellgröße:
| Nemotron-Baustein | Bedeutung für private Agentensysteme |
|---|---|
| Dynamische Auflösung | Dokumente, Tabellen, Charts und Screenshots können mit feinen Details und Layout-Kontext verarbeitet werden. |
| Native Audio- und Videoverarbeitung | Meetings, Screenrecordings, Support-Videos und gesprochene Kommentare werden nicht nur transkribiert, sondern gemeinsam mit visuellen Signalen interpretiert. |
| Multimodales RL und Verifier | Training über Bilder, Video, Audio und Text mit Abstention bei unzureichender Evidenz passt gut zu regulierten Workflows. |
Damit verschiebt sich der Modellbestand in privaten Agentensystemen. Neben Coding-, Tool-Calling- und Guardrail-Modellen braucht ein modernes Setup zunehmend einen multimodalen Spezialisten, der lange PDFs, Screenshots, Audio und Video als gemeinsame Evidenzschicht versteht. Nemotron 3 Nano Omni zeigt, wie so ein Baustein aussehen kann: nicht als Ersatz für den Conductor, sondern als leistungsfähiger Agent im Modellpool.
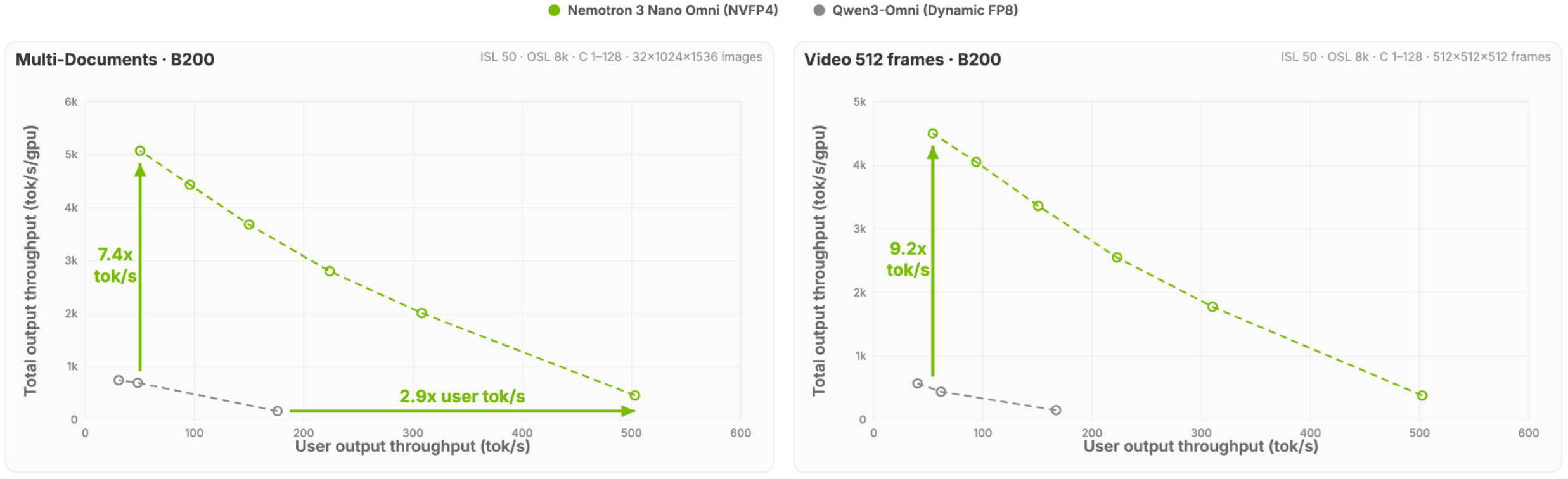
Bildquelle: NVIDIA / Hugging Face, "Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents", Figure 1.
Auch die Trainings- und Datengeschichte ist relevant. NVIDIA beschreibt synthetische Datenpipelines mit NeMo Data Designer, darunter etwa 11,4 Millionen synthetische QA-Paare aus realen PDFs für Long-Context-Dokumentenreasoning. Das führte laut Artikel zu einer 2,19-fachen Verbesserung auf MMLongBench-Doc. Für Unternehmen ist diese Richtung entscheidend: Private Agentensysteme werden nicht nur aus Modellauswahl bestehen, sondern aus Datenpipelines, synthetischen Evaluationssets und kontinuierlicher Qualitätsmessung.
Schlüsselpapers und was sie praktisch bedeuten
| Forschungsstrang | Beispiele | Praktische Konsequenz |
|---|---|---|
| SOP-basierte Orchestrierung | MetaGPT, ORCH | Interpretierbare Workflows, geeignet für regulierte Prozesse |
| Optimierbare Agentengraphen | GPTSwarm | Workflows können selbst verbessert und als Graphen versioniert werden |
| Multimodale Agenten | OmniNova, training-free multimodal orchestration | Vision, TTS, Text und Tools werden über einen Controller kombinierbar |
| Cost-Aware-Routing | FrugalGPT, xRouter, HierRouter | Kleine Modelle zuerst, Eskalation nur bei niedriger Konfidenz |
| Skill-basierte Orchestrierung | SkillOrchestra | Routing nach Fähigkeiten reduziert Trainingskosten und Routing Collapse |
| Self-evolving Agents | Fang et al., AgentNet | Langfristig entstehen dynamische Topologien statt fixer Teams |
| Evaluation | AgentBench, MASLab | Reproduzierbarkeit und Benchmarks werden Pflicht für produktive Systeme |
FrugalGPT bleibt die methodische Grundlage vieler Router: Anfragen werden zunächst an günstige Modelle gesendet und nur bei unzureichender Konfidenz eskaliert. In Unternehmensarchitekturen ist das die beste Default-Strategie, weil sie Kosten- und Privacy-Ziele gleichzeitig bedient.

Open-Source-Frameworks für die Praxis
| Framework | Paradigma | Stärken | Typischer Use Case |
|---|---|---|---|
| LangGraph | Graph-basiert, stateful | Feingranulare Kontrolle, Parallelisierung, stabile Zustandsmodelle | Komplexe Workflows mit vielen Schritten |
| AutoGen | Konversational, Role-Playing | Schnelles Prototyping, Agentendebatten | Forschung und kollaboratives Reasoning |
| CrewAI | Rollenbasiert, YAML-nah | Niedrige Lernkurve, gute Lesbarkeit | Kleine bis mittlere Agententeams |
| LlamaIndex AgentWorkflows | RAG-zentriert | Tiefe Knowledge-Base-Integration | Frage-Antwort-Systeme, Dokumentenworkflows |
| Semantic Kernel | Plugin-Architektur | Enterprise-Integration, .NET-Nähe | Microsoft-zentrierte Stacks |
| Strands Agents SDK | Loop-basiert, Agents as Tools | Multimodal und Cloud/Hybrid-freundlich | AWS-nahe agentische Workloads |
| GPTSwarm | Optimierbarer Graph | Self-improving Workflows via Graph-Optimierung | Forschung und automatische Workflow-Generierung |
Die pragmatische Empfehlung für 2026: LangGraph als Backbone, spezialisierte AutoGen-Debatten als Subgraphen, CrewAI für einfache interne Tools und MCP als Brücke zu Datenquellen und Systemen. So bleibt die Architektur kontrollierbar, ohne Forschungspotenzial abzuschneiden.
MCP und A2A: Protokolle der Agenten-Aera
MCP ist die vertikale Verbindung: Ein Agent greift standardisiert auf Tools und Daten unterhalb seiner Ausführungsebene zu. A2A ist die horizontale Verbindung: Agenten entdecken und beauftragen andere Agenten über definierte Capabilities, Task-Lebenszyklen und Message-Formate.
| Protokoll | Richtung | Kernfunktion | Bedeutung für Private AI |
|---|---|---|---|
| MCP | Vertikal | Tools, Datenquellen und lokale Systeme anbinden | Lokale Daten bleiben lokal, Tools werden auditierbar |
| A2A | Horizontal | Agenten kommunizieren über Organisationsgrenzen hinweg | Grundlage für Föderation mit Partnern oder Tochtergesellschaften |
Die Kombination ist für private Agentensysteme entscheidend. MCP kapselt Postgres, Git, Filesystem, Vector-Stores und interne REST-APIs. A2A schafft einen Pfad für künftige Föderation. Gleichzeitig müssen Sicherheitsrisiken ernst genommen werden: Prompt Injection, Tool-Spoofing, Datenexfiltration durch Tool-Kombinationen und Cross-Agent-Contamination gehören in jedes Threat Model.
Referenzarchitektur für ein privates Agentensystem
Ein realistisches On-Premise-Setup für ein mittelgroßes Unternehmen besteht aus 1 bis 2 GPU-Workstations mit je 48 GB VRAM oder einem kleinen Cluster aus RTX 6000 Ada, L40S oder vergleichbaren Karten. Entscheidend ist nicht maximale Modellgröße, sondern sauberes Routing.

Modellbestand
| Rolle | Beispielmodell | Größe | Quantisierung | Aufgabe |
|---|---|---|---|---|
| Orchestrator / Router | Qwen2.5-7B-Instruct oder Phi-4 | 7-14B | INT8 | Aufgaben zerlegen, Delegation planen |
| Coding-Spezialist | DeepSeek-Coder-V2-Lite oder Qwen2.5-Coder-7B | 7B | INT4 | Skripte, SQL, Tests, Refactorings |
| Vision / Multimodal | Qwen2.5-VL-7B-Instruct | 7B | INT4 | OCR, Tabellen, Screenshots, Diagramme |
| Tool-Caller | Hammer-2.0-7B oder Llama-3.1-8B Function-Call-Finetune | 7-8B | INT4 | Strukturierte Tool-Aufrufe |
| Planungs-Agent | GLM-4-9B oder Llama-3.3-70B on demand | 9-70B | INT4/Q5 | Schwieriges Reasoning und Eskalation |
| Embeddings | bge-m3 oder Nomic Embed | ca. 0.5B | FP16 | Retrieval und Memory |
| Guardrail | Llama-Guard-3-8B | 8B | INT8 | Policy, Safety, Vor- und Nachprüfung |
Datenfluss in der Praxis
Eine Anfrage wie "Analysiere die Vertragsänderungen in drei PDFs und erstelle ein Python-Skript, das die Klauseln in Postgres schreibt" läuft idealerweise so ab:
- Der Conductor erkennt Vision-Extraction, Reasoning, Coding und Datenbankprüfung als benötigte Skills.
- Ein Vision-Agent extrahiert Tabellen und Klauseln per OCR und schreibt strukturiertes JSON in Episodic Memory.
- Ein Reasoning-Agent vergleicht Versionen und identifiziert relevante Diff-Klauseln.
- Ein Coding-Agent generiert das SQL-Insert-Skript.
- Ein Tool-Caller prüft über MCP das Postgres-Schema und schlägt bei Bedarf Migrationen vor.
- Eine Guardrail prüft SQL-Injection-Muster, Datenabfluss und Policy-Verstöße.
- Der Conductor synthetisiert die Antwort und bietet Apply, Review oder Reject an.
Das größte Modell wird nur eskaliert, wenn Konfidenz, Neuartigkeit oder Risiko dies rechtfertigen. In vielen Workloads spart diese Architektur 60 bis 80 Prozent Inferenzkosten gegenüber einem reinen 70B-Setup.
Risiken und Gegenmaßnahmen
| Risiko | Symptom | Gegenmaßnahme |
|---|---|---|
| Latenz-Overhead | Jeder Agent-Hop addiert 200-800 ms | Hop-Budget, Parallelisierung, frühe Abbrüche |
| Reasoning-Drift | Mehr als 10 Agentenwechsel verschlechtern Ergebnisqualität | DAG begrenzen, Zwischenresultate validieren |
| Cascading Hallucinations | Fehler werden von Agent zu Agent übernommen | SOPs, Kritiker-Agenten, Tool-MVR, Konsenslayer |
| Routing Collapse | Router nutzt immer das teuerste Modell | Cost-Aware-Rewards, SkillOrchestra-Ansatz, Budgetlimits |
| State-Management | Memory und Permissions werden inkonsistent | Event-Log, explizite Context-Contracts, Least Privilege |
| MCP-Toolinjection | Bösartige Tools oder Prompts missbrauchen Rechte | Signierte Tools, Allowlisting, Sandbox, Audit-Log |
Der wichtigste operative Punkt ist Observability. Ohne Tracing wird ein Multi-Agent-System schnell zur Blackbox. Jede Delegation braucht Request-ID, Modell, Prompt-Hash, Tool-Aufruf, Kosten, Latenz, Policy-Entscheidung und Ergebnisstatus.
Trends für 2026 und 2027
Die erste Agentenwelle war Prompt Engineering. Die zweite Welle trainiert Orchestratoren per Reinforcement Learning auf gefrorenen Experten. Genau das ist attraktiv: Man muss kein Foundation Model neu trainieren, sondern optimiert die Delegation zwischen vorhandenen Modellen.
Parallel verschiebt sich die Debatte von Tool zu Society. Arbeiten wie Generative Agents, Generative Agent Simulations of 1,000 People und AgentNet zeigen, dass Agenten nicht nur Produktivitätswerkzeuge sind, sondern Simulations- und Organisationsobjekte. Unternehmen werden Agententeams designen, beobachten und governancen müssen wie heute Microservice-Landschaften.
Für Europa ist der Privacy-Aspekt besonders stark. Voll on-premise bleibt relevant für Behörden, Banken, Pharma und Verteidigung. Hybridarchitekturen werden für die meisten Unternehmen realistischer sein: sensible Daten lokal, schweres Reasoning über souverane Cloud-Endpunkte oder Confidential Computing.
Fazit
Orchestrierte, spezialisierte Modelle sind 2026 keine Spekulation mehr, sondern eine produktionsnahe Architekturklasse. Die Lehre aus MoE, FrugalGPT, xRouter, SkillOrchestra, LangGraph, MCP und A2A ist konsistent: Ein einzelnes großes Modell ist selten die ökonomisch oder regulatorisch beste Antwort.
Private Agentensysteme sollten SLM-zentrisch starten, große Modelle selektiv eskalieren, MCP als Tool- und Datenstandard nutzen, A2A als Föderationspfad beobachten, Agent-Hops begrenzen und Observability von Anfang an einbauen.
Die Zukunft gehört nicht nur dem größten Modell. Sie gehört Architekturen, die wissen, welches Modell wann genug ist.
Quellen und weiterführende Literatur
- Belcak et al.: "Small Language Models are the Future of Agentic AI" - https://arxiv.org/abs/2506.02153
- Liu et al.: "A Survey on Inference Optimization Techniques for Mixture of Experts Models" - https://arxiv.org/abs/2412.14219
- Sun et al.: "LLM-based Multi-Agent Reinforcement Learning" - https://arxiv.org/abs/2405.11106
- Schick et al.: "Toolformer" - https://arxiv.org/abs/2302.04761
- Hong et al.: "MetaGPT" - https://arxiv.org/abs/2308.00352
- Zhuge et al.: "GPTSwarm" - https://arxiv.org/abs/2402.16823
- Chen, Zaharia, Zou: "FrugalGPT" - https://arxiv.org/abs/2305.05176
- AgentBench - https://arxiv.org/abs/2308.03688
- MASLab - https://arxiv.org/abs/2505.16988
- Model Context Protocol - https://en.wikipedia.org/wiki/Model_Context_Protocol
- NVIDIA / Hugging Face: "Introducing NVIDIA Nemotron 3 Nano Omni: Long-Context Multimodal Intelligence for Documents, Audio and Video Agents" - https://huggingface.co/blog/nvidia/nemotron-3-nano-omni-multimodal-intelligence
- NVIDIA Nemotron 3 Nano Omni technical report - https://arxiv.org/abs/2604.24954




