
Private AI: LLMs auf eigener Infrastruktur — 60 % günstiger als OpenAI
Warum europäische Unternehmen KI ins eigene Haus holen und welche konkreten Wirtschaftlichkeitsrechnungen dahinterstehen.
Der 8,4-Milliarden-Dollar-Weckruf
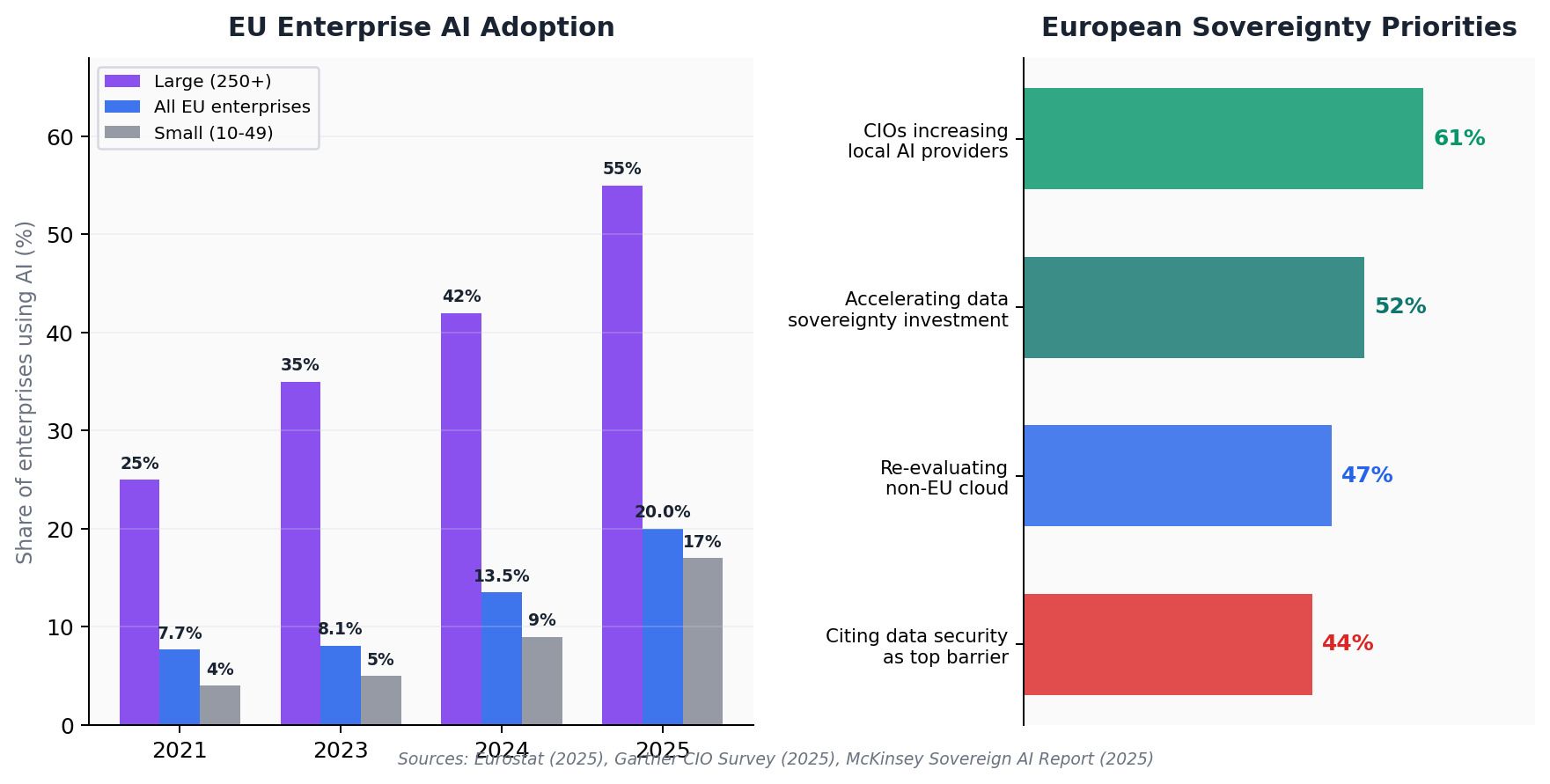
Die Ausgaben von Unternehmen für Large-Language-Model-APIs haben sich 2025 auf 8,4 Milliarden Dollar verdoppelt, und 72 % der Unternehmen planen, ihre KI-Budgets in diesem Jahr weiter zu erhöhen. Doch hinter dem Adoptionsboom formiert sich eine leisere Gegenbewegung. Laut Kongs Enterprise-AI-Report 2025 nennen 44 % der Organisationen Datenschutz und Sicherheit als größtes Hindernis für die LLM-Adoption. Jeder Prompt, der an OpenAI, Anthropic oder Google gesendet wird, durchläuft externe Server, unterliegt Aufbewahrungsrichtlinien Dritter und fällt unter Rechtsordnungen, die möglicherweise nicht mit den eigenen übereinstimmen.
Für europäische Unternehmen — die unter dem weltweit strengsten Regulierungsrahmen operieren — entsteht eine fundamentale Spannung. Man braucht KI, um wettbewerbsfähig zu bleiben, aber man braucht Datensouveränität, um compliant zu bleiben. Die Lösung ist nicht, KI zu meiden. Sondern sie zu besitzen.
Private AI — die Praxis, Large Language Models auf selbst kontrollierter Infrastruktur zu betreiben — hat sich von einer experimentellen Kuriosität zu einer tragfähigen, oft überlegenen Alternative zu kommerziellen API-Diensten entwickelt. Open-Source-Modelle erreichen oder übertreffen mittlerweile GPT-4-Niveau bei den meisten Enterprise-Aufgaben. Die Deployment-Tools haben sich dramatisch vereinfacht. Und die Wirtschaftlichkeit, einst prohibitiv, spricht nun bei hohen Volumina für Self-Hosting: Organisationen, die täglich große Mengen an Tokens verarbeiten, können 40–60 % Kosteneinsparungen gegenüber kommerziellen APIs erzielen, einige berichten von Einsparungen bis zu 83 %.
Dieser Artikel liefert eine konkrete, zahlengetriebene Analyse, wann und warum Private AI sinnvoll ist — von der regulatorischen Landschaft, die es für EU-Unternehmen dringend macht, über die wahren Gesamtbetriebskosten bis hin zum technischen Stack für Produktions-Deployments und den Fine-Tuning-Fähigkeiten, die ein generisches Modell in einen Wettbewerbsvorteil verwandeln.
Der regulatorische Druckkessel: DSGVO trifft auf den EU AI Act
Europäische Unternehmen bevorzugen nicht nur Datensouveränität — sie müssen sie zunehmend nachweisen. Das regulatorische Umfeld 2026 schafft kumulative Compliance-Pflichten, die KI-APIs von Drittanbietern zu einem wachsenden Haftungsrisiko machen.
DSGVO: Die Basis, die nach wie vor schmerzt
Die Datenschutz-Grundverordnung bleibt das Fundament. Jedes KI-System, das personenbezogene Daten von EU-Bürgern verarbeitet, muss eine Rechtsgrundlage nachweisen, Datenschutz durch Technikgestaltung und datenschutzfreundliche Voreinstellungen implementieren und jederzeit Compliance belegen können. Wenn Kundendaten über eine externe LLM-API gesendet werden, wird ein Auftragsverarbeiter (der API-Anbieter) in die Verarbeitungskette eingeführt. Das erfordert einen Auftragsverarbeitungsvertrag, Dokumentation der Rechtsgrundlage für die Übermittlung und fortlaufende Gewährleistung, dass die Speicher- und Trainingspraktiken des Anbieters die eigenen Pflichten nicht verletzen.
Self-Hosting eliminiert diese gesamte Risikokategorie: Die Prompts verlassen nie das eigene Netzwerk, und es gibt keinen Drittanbieter-Auftragsverarbeiter zu auditieren.
Der EU AI Act: Bußgelder, die die DSGVO übertreffen
Der EU AI Act — das weltweit erste umfassende KI-Gesetz — setzt seit August 2024 schrittweise Pflichten um. Der kritischste Termin ist der 2. August 2026. An diesem Datum werden die Anforderungen für Hochrisiko-KI-Systeme unter Anhang III vollständig durchsetzbar. Die Bußgeldstruktur übertrifft sogar die DSGVO: bis zu 35 Millionen Euro oder 7 % des weltweiten Jahresumsatzes für verbotene KI-Praktiken, und bis zu 15 Millionen Euro oder 3 % für Verstöße gegen Hochrisiko-Systempflichten.
| Datum | Meilenstein | Auswirkung |
|---|---|---|
| Aug 2024 | AI Act tritt in Kraft | Rechtsrahmen etabliert |
| Feb 2025 | Verbotene KI-Praktiken durchgesetzt | Social Scoring, manipulative KI verboten |
| Aug 2025 | GPAI-Transparenzpflichten | LLM-Anbieter müssen Trainingsdaten offenlegen |
| 2. Aug 2026 | Hochrisiko-KI volle Compliance | Konformitätsbewertungen, EU-Datenbankregistrierung |
| Aug 2027 | KI in regulierten Produkten | Medizinprodukte, Fahrzeuge mit eingebetteter KI |
Datensouveränität ist zur Chefsache geworden
Laut Gartners CIO & IT Leader Survey 2025 planen 61 % der CIOs und IT-Entscheider in Westeuropa, ihre Abhängigkeit von lokalen Cloud- und KI-Anbietern zu erhöhen. Darüber hinaus erwarten 52 %, Investitionen in Datensouveränitätsinitiativen zu beschleunigen, und 47 % evaluieren aktiv nicht-europäische Cloud-Abhängigkeiten neu. McKinsey schätzt, dass souveräne KI-Fähigkeiten in Europa bis 2030 einen Wert von bis zu 480 Milliarden Euro jährlich freisetzen könnten.
Die Kostengleichung: Wann Self-Hosting die API schlägt
Die Wirtschaftlichkeit von Private AI hängt von drei Variablen ab: dem Token-Volumen, dem Modell-Tier zum Vergleich und der Fähigkeit, eine hohe GPU-Auslastung aufrechtzuerhalten. Das Verständnis der Schwellenwerte ist essenziell.
API-Preise 2026: Ein stark geschichteter Markt
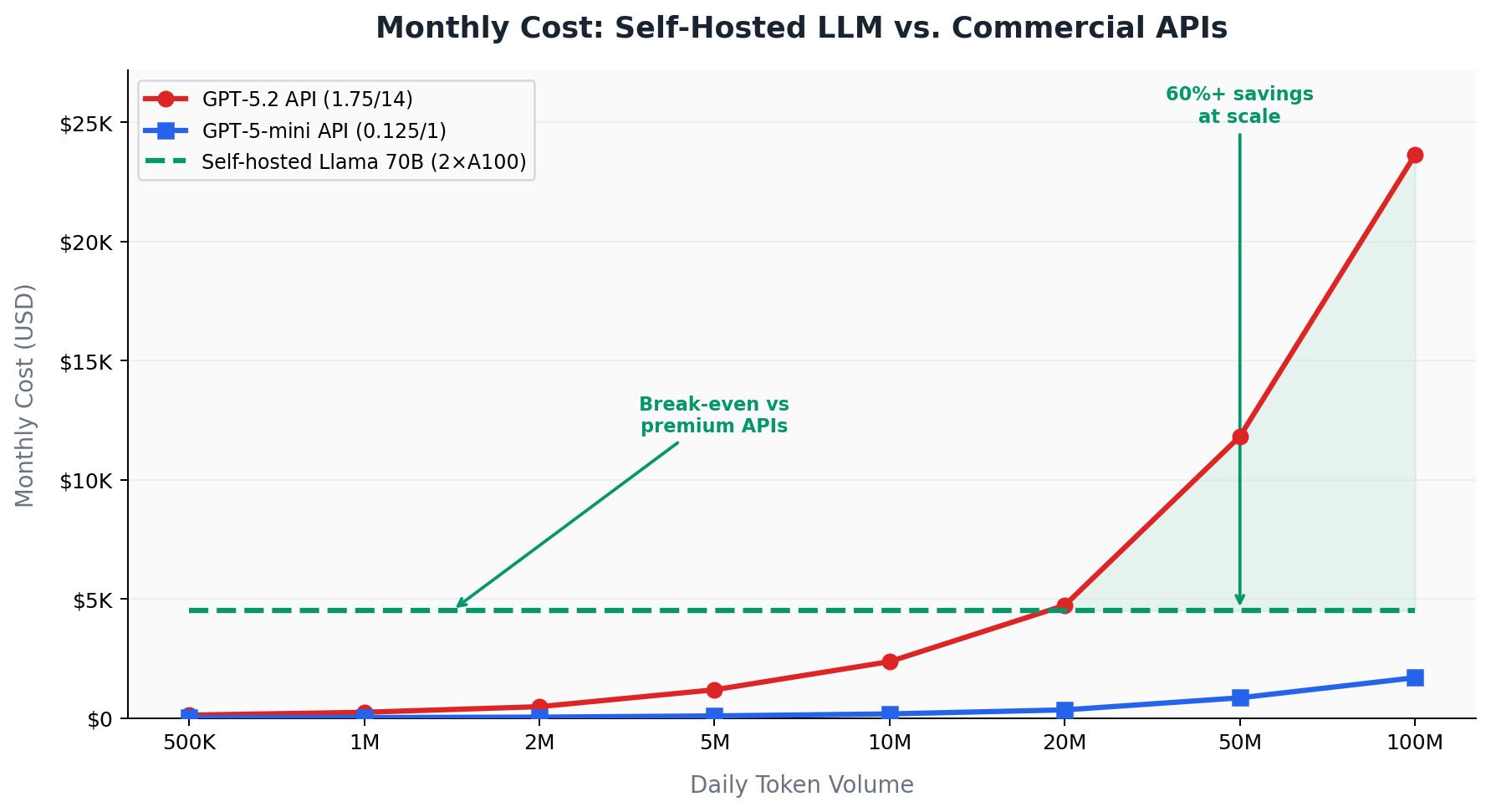
Die Preise für kommerzielle LLM-APIs haben sich dramatisch ausdifferenziert. OpenAIs GPT-5.2 kostet 1,75 Dollar pro Million Input-Tokens und 14,00 Dollar pro Million Output-Tokens. GPT-5-mini läuft bei 0,125/1,00 Dollar — ein 14-facher Unterschied. DeepSeek V3.2 bietet wettbewerbsfähige Qualität für nur 0,14/0,28 Dollar pro Million Tokens.
| Modell / Option | Input / 1M Tok | Output / 1M Tok | Monatlich bei 1M/Tag |
|---|---|---|---|
| GPT-5.2 (Premium) | $1,75 | $14,00 | ~$7.875 |
| GPT-5-mini (Budget) | $0,125 | $1,00 | ~$563 |
| DeepSeek V3.2 | $0,14 | $0,28 | ~$210 |
| Self-hosted Llama 70B | Fix | Fix | ~$4.500 |
Die Break-Even-Analyse
Gegenüber Premium-Modellen wie GPT-4o oder Claude Sonnet (7,50–9,00 Dollar pro Million Tokens gemischt) amortisiert sich Self-Hosting bei etwa 5–10 Millionen Tokens pro Monat. Gegenüber Budget-APIs wie GPT-4o mini oder DeepSeek (0,15–0,40 Dollar pro Million Tokens) steigt der Break-Even auf 50–100 Millionen Tokens monatlich. Für europäische Betreiber bei 0,25–0,30 Dollar/kWh treiben Energiekosten den Break-Even um 40–60 % nach oben.
Faustregel: Organisationen, die täglich über 2 Millionen Tokens verarbeiten, sollten Self-Hosting ernsthaft evaluieren. Unter diesem Schwellenwert sind API-Kosten typischerweise niedriger. Über 100 Millionen Tokens täglich kann Self-Hosting 40–60 % einsparen — besonders gegenüber Premium-Modellen.
Versteckte Kosten, die nicht ignoriert werden dürfen
Reine GPU-Kosten machen nur 30–40 % der tatsächlichen Self-Hosting-Investition aus. Ein realistischer TCO-Multiplikator liegt bei 1,3x bis 2,0x der Basis-GPU-Kosten. Engineering-Personal ist oft der größte versteckte Kostenfaktor — ein Mid-Level-MLOps-Engineer in Europa kostet 80.000–120.000 Euro jährlich. Strom und Kühlung betragen das 1,5–2-Fache der GPU-Nennleistung. Hardware-Abschreibung: Eine 30.000-Dollar-H200-GPU verliert über 36 Monate etwa 833 Dollar pro Monat.
Der technische Stack: Von der Modellauswahl bis zum Produktionsbetrieb
Ein privates LLM in Produktion zu deployen, ist nicht mehr die Heldentat, die es 2023 noch war. Das Tool-Ökosystem ist dramatisch gereift, und ein gut gewählter Stack kann in Tagen von null auf Produktion gehen.
Das richtige Open-Source-Modell wählen
Die Qualitätslücke zwischen Open-Source- und proprietären Modellen hat sich signifikant verringert. Führende Optionen Anfang 2026 sind Metas Llama 3.3 (8B und 70B), Alibabas Qwen 2.5 (bis 72B), DeepSeek V3.2 (sparse MoE) und OpenAIs gpt-oss-120B — das erste vollständig offene Modell des Unternehmens seit GPT-2, veröffentlicht unter Apache 2.0. Qwen 2.5-72B erreicht 95 %+ Parität mit GPT-4 auf MMLU und HumanEval. Für strukturierte Aufgaben bewältigen Open-Source-Modelle 80 %+ der Enterprise-Use-Cases ohne nennenswerten Qualitätsverlust.
Inference-Engines: Ollama für Entwicklung, vLLM für Produktion
| Kriterium | Ollama | vLLM |
|---|---|---|
| Haupteinsatz | Entwicklung, Prototyping, Einzelnutzer | Produktion, hohe Parallelität |
| Setup | Ein einziger Befehl | CUDA, Treiber, Python-Konfiguration |
| Durchsatz (70B) | ~484 Tok/s | ~8.033 Tok/s (16,6x) |
| Parallelität | Bricht bei 128 Nutzern zusammen | 100 % Erfolg bei 128 Nutzern |
| OpenAI-kompatibel | Ja | Ja |
| Kerntechnologie | llama.cpp-Wrapper | PagedAttention, Continuous Batching |
Die OpenAI-kompatible API: Ihre Migrationsversicherung
Ob mit Ollama, vLLM oder LM Studio — der Anwendungscode bleibt im Wesentlichen identisch. Der Standard-Endpunkt /v1/chat/completions funktioniert bei allen Anbietern gleich. Das bedeutet: Man kann mit kommerziellen APIs starten, schrittweise auf selbstgehostete Modelle migrieren und zwischen Anbietern wechseln — ohne Anpassungen am Anwendungscode.
from openai import OpenAI # Gleiche Client-Bibliothek, andere Base-URL client = OpenAI( base_url="https://your-internal-llm.company.eu:8000/v1", api_key="your-internal-token" ) response = client.chat.completions.create( model="meta-llama/Llama-3.3-70B-Instruct", messages=[ {"role": "system", "content": "Sie sind ein hilfreicher Assistent."}, {"role": "user", "content": "Fassen Sie den Q4-Compliance-Bericht zusammen."} ], temperature=0.1 ) # Daten verlassen nie Ihr Netzwerk.
Fine-Tuning: Wo Private AI zum Wettbewerbsvorteil wird
Das überzeugendste strategische Argument für Private AI ist weder Kosten- noch Compliance-bezogen — es ist Anpassbarkeit. Fine-Tuning verwandelt ein Allzweck-Modell in einen Domänenspezialisten, der die eigene Terminologie versteht, die eigenen Prozesse befolgt und Ergebnisse liefert, die auf die eigenen Standards kalibriert sind.
LoRA: Fine-Tuning ohne die großen Kosten
Low-Rank Adaptation (LoRA) hat die Wirtschaftlichkeit von Fine-Tuning revolutioniert. Statt alle Parameter neu zu trainieren, trainiert LoRA kleine Adapter-Module, die nur 0,1 % der Gesamtparameter repräsentieren. Bei einem 70B-Modell sind das ca. 70 Millionen Parameter mit 0,14 GB Speicherbedarf. Fine-Tuning kann auf einer einzigen GPU in Stunden für 15–40 Dollar pro Durchlauf abgeschlossen werden. Together AIs Forschung zeigt, dass feinabgestimmte 27B-Modelle Claude Sonnet 4 bei spezialisierten Aufgaben um 60 % übertreffen können — bei 10–100-fach geringeren Kosten.
Der entscheidende Unterschied: Wer über OpenAI feinabstimmt, erhält ein proprietäres Modell, das nur über deren API zugänglich ist. Wer Open-Source-Modelle mit LoRA feinabstimmt, besitzt den Adapter: Er kann überall deployt, versionskontrolliert und ohne Token-Kosten betrieben werden.
Wo Fine-Tuning verteidigbaren Wert schafft
Die Use Cases mit dem höchsten ROI teilen gemeinsame Merkmale: domänenspezifische Terminologie, konsistentes Output-Formatting und hochvolumige repetitive Aufgaben. In Rechtsabteilungen extrahieren feinabgestimmte Modelle Vertragsklauseln mit 30–40 % höherer Genauigkeit. Im Gesundheitswesen folgen auf klinischen Notizen trainierte Modelle Dokumentationsstandards, die generische Modelle verletzen. Im Kundenservice halten feinabgestimmte Modelle Markenstimme und Eskalationsprotokolle ein, die Prompt Engineering nur inkonsistent erreicht.
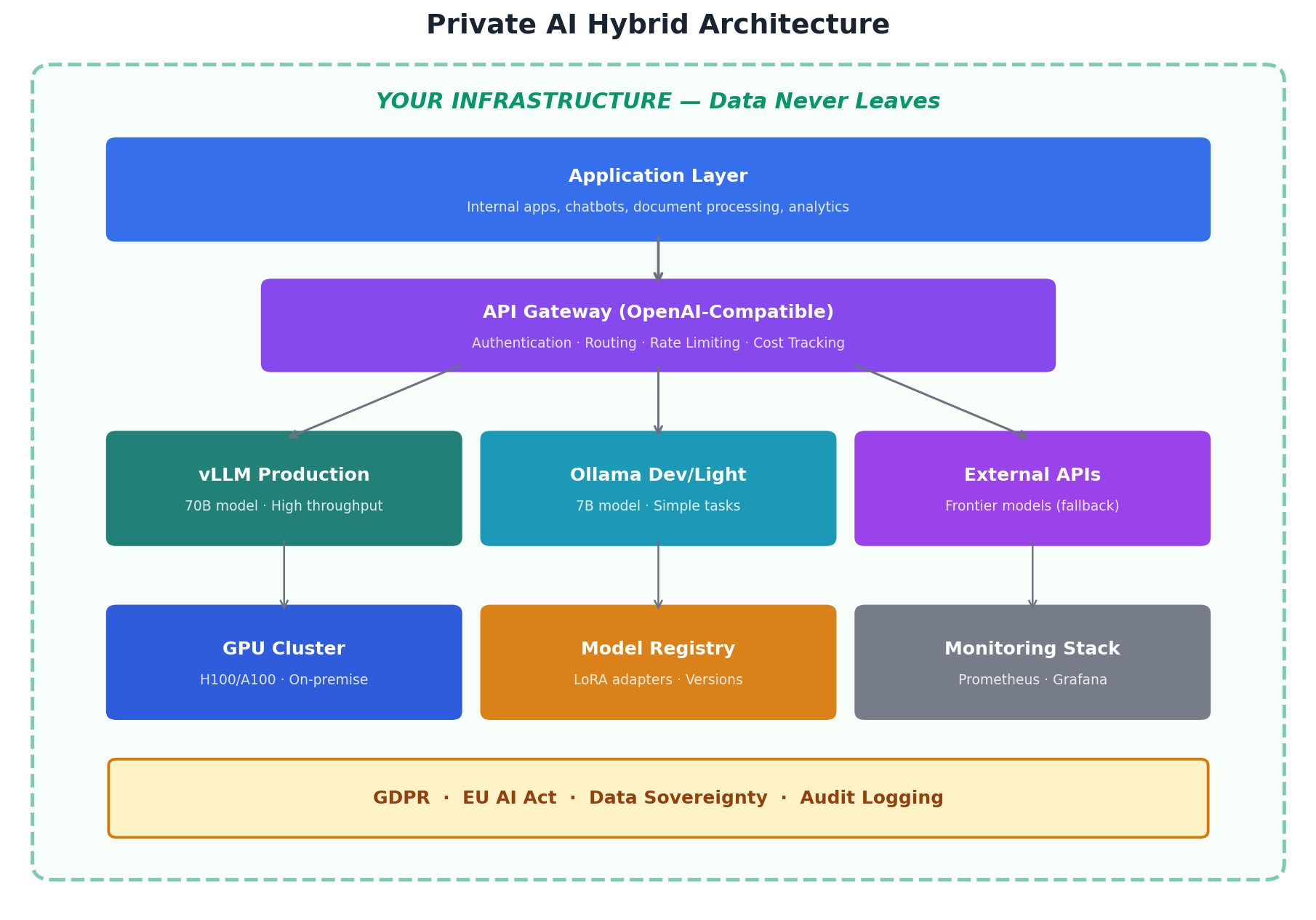
Die hybride Architektur: Der pragmatische Weg
Die effektivste Architektur kombiniert private Modelle für hochvolumige, sensible oder domänenspezifische Workloads mit kommerziellen APIs für Frontier-Fähigkeiten und schnelles Experimentieren. Ein API-Gateway leitet jede Anfrage basierend auf Datensensitivität, Aufgabenkomplexität und Kosteneffizienz.
Ein praktischer Migrationsfahrplan
| Phase | Zeitraum | Aktivitäten |
|---|---|---|
| 1. Audit | Wo 1–4 | LLM-Nutzung inventarisieren. Nach Sensitivität, Volumen, Qualitätsanforderungen klassifizieren. Auf AI-Act-Compliance mappen. |
| 2. Pilot | Wo 5–12 | Ollama + vLLM auf GPU-Infrastruktur deployen. Mit einem risikoarmen, volumenstarken Use Case starten. 2 Wochen Shadow-Modus. |
| 3. Migration | Wo 13–24 | Validierte Use Cases migrieren. API-Gateway implementieren. Fine-Tuning für die wertvollste Domäne beginnen. |
| 4. Optimierung | Laufend | Use Cases erweitern. Batch-Processing, Caching, Model-Cascading hinzufügen. Kleinere Modelle evaluieren. |
Fazit: Souveränität ist die neue Skalierbarkeit
Der Wandel zu Private AI ist primär keine Kostenoptimierung — auch wenn die Einsparungen real sind. Es ist eine strategische Neupositionierung, die regulatorische Compliance, Datensouveränität, Wettbewerbsdifferenzierung durch Fine-Tuning und operative Kontrolle adressiert.
Europäische Unternehmen stehen vor einem einzigartigen Zeitfenster. Die August-2026-Deadline des EU AI Acts erzeugt Dringlichkeit. Open-Source-Modelle haben Qualitätsparität erreicht. Deployment-Tools haben sich so weit vereinfacht, dass ein kompetentes DevOps-Team Produktions-Inferenz in Tagen aufsetzen kann. Und die Kostenökonomie spricht nun für Self-Hosting bei jeder Organisation, die nennenswerte KI-Workloads verarbeitet.
Private AI bedeutet nicht, die Cloud abzulehnen. Es bedeutet, die Infrastruktur, Skills und strategische Klarheit zu haben, KI zu eigenen Bedingungen einzusetzen — externe Dienste zu wählen, weil sie tatsächlich besser sind, nicht weil sie die einzige Option darstellen. In einer Welt, in der KI-Fähigkeiten zunehmend den Wettbewerbsvorteil definieren, ist der Besitz des eigenen KI-Stacks so fundamental wie der Besitz der eigenen Daten.





